Không có thư viện vẽ biểu đồ Python nào là "tốt nhất" một cách tuyệt đối, và ai nói với bạn điều ngược lại thì chắc chắn đang muốn bán cho bạn thứ gì đó. Câu trả lời trung thực là lĩnh vực này chia thành một nhóm nhỏ các công cụ, mỗi công cụ thắng ở một công việc cụ thể: một biểu đồ tĩnh chất lượng xuất bản, một dòng lệnh thống kê, một dashboard tương tác, một đặc tả khai báo bạn có thể quản lý phiên bản, hay một biểu đồ phải trụ vững trước hàng trăm triệu điểm dữ liệu. Bài đánh giá này điểm qua các thư viện đáng quan tâm, từng thư viện thực sự giỏi ở đâu, đổ vỡ ở đâu, và — vì trang này nói về việc xây dựng bằng Python cho thị trường tài chính — chúng xử lý biểu đồ nến và chuỗi thời gian lớn như thế nào.
Mỗi con số về số sao, lượt tải và giấy phép dưới đây đều đã được đối chiếu với các nguồn gốc (GitHub, PyPI, tài liệu chính thức) vào giữa năm 2026. Nơi nào con số là trường hợp tốt nhất do chính nhà cung cấp tự công bố, điều đó đều được ghi chú rõ.
Mô hình tư duy: tĩnh so với tương tác
Ngã rẽ đầu tiên là output thuộc loại ảnh tĩnh (PNG/SVG/PDF, dựng một lần) hay biểu đồ tương tác (HTML/JS, kéo-thu phóng-rê chuột trong trình duyệt).
- Tĩnh: Matplotlib, Seaborn, Plotnine — và Pygal, vốn xuất ra SVG có chút tương tác.
- Tương tác: Plotly, Bokeh, Altair.
Ngã rẽ thứ hai — chỉ "cắn" khi dữ liệu của bạn lớn lên — là nơi các điểm được vẽ ra: trong trình duyệt (phía client, WebGL) hay được tổng hợp sẵn trên server thành một ảnh. Sự phân biệt đó chính là toàn bộ câu chuyện của "nhóm thư viện cho dữ liệu lớn" ở phần sau, và đó là điều mà hầu hết các bài đánh giá bỏ qua.
Matplotlib — nền móng mà mọi thứ đứng trên đó
Matplotlib là nền tảng cốt lõi của việc vẽ biểu đồ trong Python. Nó không chỉ là một thư viện; nó là engine dựng hình mà Seaborn, các giá trị mặc định của Plotnine, mplfinance và cả chục thư viện khác xây dựng bên trên. Giấy phép của nó rất thoáng — chính thức "dựa trên giấy phép PSF" và tương thích BSD, nên bạn có thể đưa nó vào một sản phẩm thương mại độc quyền và bán đi mà không phải đắn đo (tài liệu giấy phép).
Điểm mạnh. Toàn quyền kiểm soát. Nếu bạn có thể mô tả một dấu vẽ trên canvas 2D, Matplotlib có thể vẽ nó, và nó xuất ra PDF/SVG vector sắc nét để in ấn. Nó được cài đặt ở khắp mọi nơi và mọi lỗi bạn từng gặp đều đã có sẵn câu trả lời trên Stack Overflow.
Điểm yếu. API của nó nổi tiếng là "hai đầu" — một giao diện pyplot có trạng thái theo phong cách MATLAB và một giao diện hướng đối tượng Figure/Axes — và các bài hướng dẫn trộn lẫn chúng tự do, đó chính xác là lý do "tại sao bạn ghét matplotlib" trở thành một thể loại riêng. Các giá trị mặc định đã lỗi thời, và để tạo kiểu cho một biểu đồ trông hiện đại thì tốn không ít dòng code.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(df.index, df["close"], lw=1.2)
ax.set_title("BTC-USD daily close")
fig.savefig("btc.png", dpi=150, bbox_inches="tight")
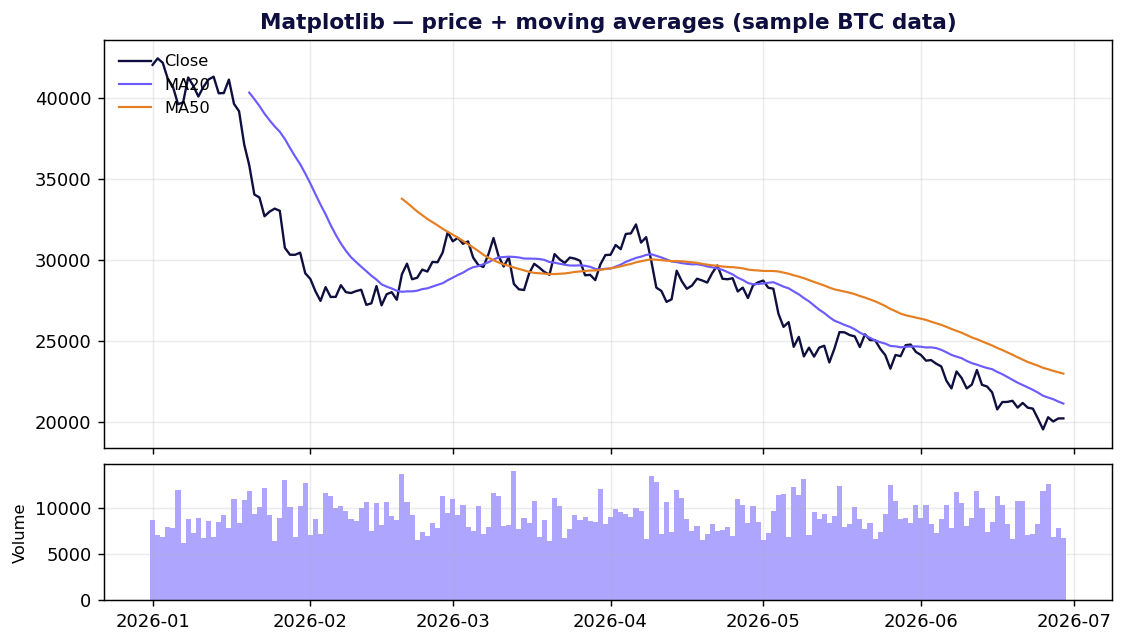
Dùng nó khi bạn cần một biểu đồ tĩnh, sẵn sàng để in, hoặc bạn đang xây dựng một công cụ cấp cao hơn và muốn một canvas mà bạn toàn quyền kiểm soát.
Seaborn — đồ họa thống kê không cần dài dòng
Seaborn là một lớp mỏng, có quan điểm rõ ràng, nằm trên Matplotlib (BSD-3-Clause) biến mười dòng loay hoay với trục thành một dòng. Nó "cung cấp giao diện cấp cao để vẽ các đồ họa thống kê đẹp mắt" và tích hợp chặt chẽ với pandas — phân phối, hồi quy, heatmap và các đồ thị nhỏ phân mảnh đều chỉ cần một lệnh gọi.
import seaborn as sns
sns.set_theme()
sns.lineplot(data=returns, x="date", y="ret", hue="symbol")
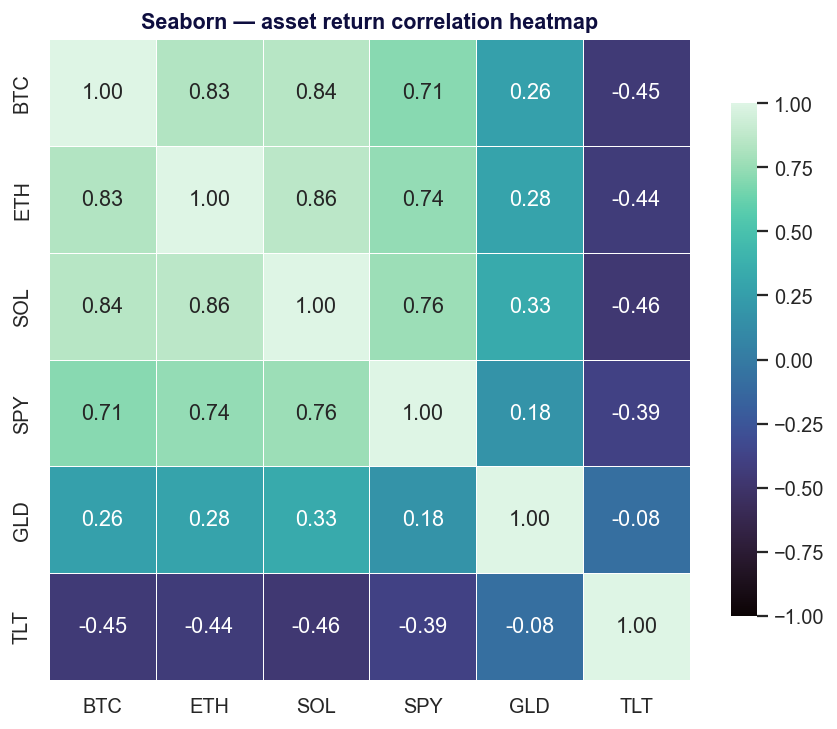
Điểm mạnh. Giá trị mặc định thống kê thuộc hàng tốt nhất; đẹp ngay từ đầu; là lựa chọn đầu tiên hiển nhiên cho phân tích dữ liệu khám phá.
Điểm yếu. Nó thừa hưởng bản chất tĩnh của Matplotlib (không tương tác) và, khi bạn cần một biểu đồ mà nó không có hàm sẵn, bạn lại phải quay về Matplotlib thô. Nó là một lớp tiện lợi, không phải là lối thoát khỏi engine.
Dùng nó khi bạn đang làm EDA trên một DataFrame và muốn nhanh chóng có heatmap tương quan, phân phối hay biểu đồ hồi quy.
Plotly — lựa chọn tương tác mặc định
Plotly.py là lựa chọn tương tác được áp dụng rộng rãi nhất. Nó được cấp phép MIT, xây dựng trên plotly.js, và các con số thì không hề sít sao: khoảng 18,6k sao GitHub và khoảng 1,24 tỷ lượt tải PyPI tính từ trước đến nay — vào cỡ 61 triệu lượt tải trong 30 ngày gần nhất (PyPI · thống kê lượt tải). Tooltip khi rê chuột, thu phóng, kéo và bật/tắt chú giải đều có sẵn miễn phí, và cùng một biểu đồ sẽ hiển thị được trong notebook, trong ứng dụng Dash, hay một file HTML tĩnh.
import plotly.graph_objects as go
fig = go.Figure(go.Candlestick(
x=df.index, open=df.open, high=df.high, low=df.low, close=df.close,
))
fig.update_layout(title="BTC-USDT", xaxis_rangeslider_visible=False)
fig.show()
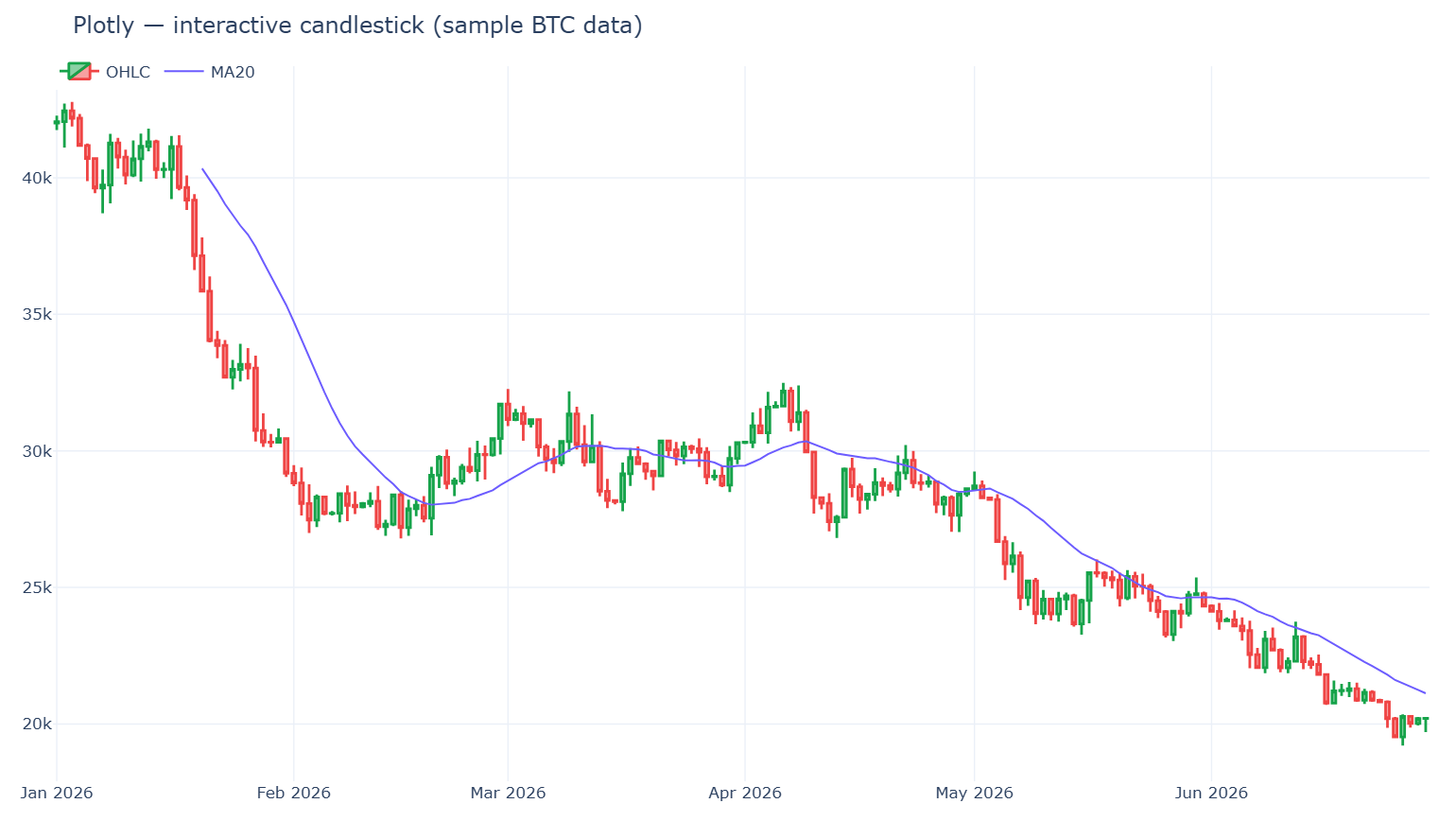
Điểm mạnh. Tính tương tác mà không cần JavaScript; các loại biểu đồ tài chính hạng nhất (go.Candlestick, go.Ohlc); con đường tới một dashboard hoàn chỉnh (Dash) rất ngắn.
Điểm yếu. Gói plotly.js khá nặng — một cái giá thực sự đối với các trang nhạy cảm về thời gian tải (phân tích thời gian tải gói). Và có một trần dựng hình cứng: với các trace WebGL (go.Scattergl) bạn có thể biểu diễn tối đa khoảng 1 triệu điểm, nhưng trình duyệt chỉ cho phép 8–16 ngữ cảnh WebGL trên mỗi trang, nên trong thực tế bạn chỉ có được 4–8 biểu đồ WebGL trước khi gặp "Too many active WebGL contexts" (tài liệu hiệu năng Plotly). Việc thu phóng/kéo tương tác mượt mà thực tế chỉ trụ được tới khoảng 100–200k điểm.
Dùng nó khi bạn muốn biểu đồ hoặc dashboard tương tác, đặc biệt là loại tài chính, và chuỗi của bạn nằm trong khoảng từ hàng nghìn đến vài triệu điểm.
Bokeh — tương tác được xây cho dữ liệu lớn và dữ liệu luồng
Bokeh (BSD-3-Clause, khoảng 20,4k sao / 4,3k fork) là đối thủ tương tác chính của Plotly, với một trọng tâm khác: nó là "một thư viện trực quan hóa tương tác cho các trình duyệt web hiện đại" hướng tới các tập dữ liệu lớn và dữ liệu luồng cùng các ứng dụng do server điều khiển (server Bokeh có thể đẩy cập nhật trực tiếp tới một biểu đồ qua websocket).
Một điểm cần lưu ý trung thực mà tiếp thị sẽ không nói cho bạn: "hiệu năng cao" một phần là tự mô tả. Các báo cáo thực tế cho thấy rê chuột/tooltip bị chậm lại trên các tập dữ liệu nhỏ chỉ khoảng 50k điểm, nên nó không tự động nhanh trên dữ liệu khổng lồ — bạn vẫn phải dùng đến việc tổng hợp (xem bên dưới). Hãy coi lợi thế của Bokeh là dữ liệu luồng và kiến trúc ứng dụng, không phải số lượng điểm thô.
from bokeh.plotting import figure, show
p = figure(x_axis_type="datetime", title="BTC-USD", height=350)
p.line(df["date"], df["close"])
show(p)
Dùng nó khi bạn đang xây dựng một dashboard cập nhật trực tiếp hoặc một ứng dụng dữ liệu do Python điều khiển và muốn kiểm soát tính tương tác ở phía server.
Altair — một ngữ pháp đồ họa khai báo
Altair là một thư viện khai báo: bạn mô tả cái gì cần mã hóa (cột này vào x, cột kia vào màu) và engine Vega-Lite quyết định vẽ như thế nào. Biểu đồ là các đặc tả JSON, khiến chúng dễ kết hợp và dễ so sánh khác biệt.
Cái bẫy mà mọi người mới đều gặp: theo mặc định, Altair từ chối vẽ quá 5.000 hàng, tung ra lỗi MaxRowsError. Đó là một rào chắn có chủ đích (Altair nhúng dữ liệu dưới dạng JSON ngay trong đặc tả), không phải là sự bất lực trong việc xử lý dữ liệu — và chỉ cần một dòng lệnh để gỡ bỏ:
import altair as alt
alt.data_transformers.disable_max_rows() # hoặc dùng backend VegaFusion cho ~100k+
alt.Chart(df).mark_line().encode(x="date:T", y="close:Q")
Đây là một nguồn gây bực bội lặp đi lặp lại chính bởi vì lỗi xuất hiện ngay trên thứ tưởng chừng là một frame "nhỏ" 35k hàng (tài liệu về tập dữ liệu lớn).
Dùng nó khi bạn coi trọng các đặc tả biểu đồ ngắn gọn, khai báo, có thể tái lập và dữ liệu của bạn ở mức vừa phải — hoặc bạn sẵn lòng thiết lập VegaFusion cho các frame lớn hơn.
Plotnine và Pygal — bổ sung cho lĩnh vực
- Plotnine là một bản chuyển gần như trung thành của ngữ pháp đồ họa
ggplot2trong R (cấp phép MIT). Nếu bạn đến từ R hoặc bạn tư duy theo kiểuaes()+ cácgeom_*xếp lớp, đây là API tự nhiên nhất trong danh sách này. Nó dựng hình thông qua Matplotlib, nên nó là tĩnh.
python
from plotnine import ggplot, aes, geom_line
(ggplot(df, aes("date", "close")) + geom_line())
- Pygal xuất ra các biểu đồ SVG — không phụ thuộc độ phân giải, có thể tạo kiểu bằng CSS, và rất nhỏ gọn để nhúng vào một báo cáo hay trang web. Đây là một lựa chọn ngách: tuyệt vời cho các biểu đồ vector sạch sẽ trên một trang web, không được xây cho dữ liệu lớn hay tương tác nặng.
Khi dữ liệu của bạn lớn lên: nhóm thư viện cho dữ liệu lớn
Đây là nơi những lựa chọn ngây thơ sụp đổ. Một khi đã vượt quá một triệu điểm, bạn không thể chỉ đơn giản giao chúng cho trình duyệt. (Để nói cho chính xác về một lầm tưởng: trình duyệt có thể biểu diễn khoảng 1 triệu điểm WebGL — chính sự mượt mà khi tương tác mới suy giảm, chứ không phải một sự sập cứng.) Hai chiến lược khắc phục điều này:
1. Raster hóa phía server — Datashader. Thay vì gửi các điểm tới trình duyệt, Datashader (BSD-3-Clause) chia chúng vào một lưới 2D kích thước cố định và dựng lưới đó thành một ảnh, "bảo toàn trung thực phân phối của dữ liệu". Con số nổi bật của nó: một tỷ điểm trong khoảng một giây trên một laptop 16 GB, mở rộng ra ngoài bộ nhớ và lên GPU thông qua Dask (giới thiệu · hướng dẫn dữ liệu lớn của HoloViews). Hãy coi con số một tỷ điểm mỗi giây là trường hợp tốt nhất do nhà cung cấp đưa ra — nhưng cách tiếp cận (chia lại lưới mỗi lần thu phóng/kéo) thực sự là cách đúng đắn cho dữ liệu dày đặc.
import datashader as ds, datashader.transfer_functions as tf
cvs = ds.Canvas(plot_width=900, plot_height=400)
agg = cvs.points(df, "t", "price") # df có thể là một Dask frame lớn hơn RAM
img = tf.shade(agg)
2. Lấy mẫu giảm theo khung nhìn — plotly-resampler. Cách này giữ nguyên toàn bộ tính tương tác của Plotly nhưng chỉ luôn dựng những điểm mà bạn thực sự nhìn thấy. Tổng hợp MinMaxLTTB mặc định của nó giảm mỗi trace xuống còn khoảng 1.000 điểm được vẽ cho khung nhìn hiện tại, rồi lấy lại dữ liệu khi bạn thu phóng — bản demo trực quan hóa hơn 110 triệu điểm dữ liệu theo cách này (bài báo).
from plotly_resampler import FigureResampler
import plotly.graph_objects as go
fig = FigureResampler(go.Figure())
fig.add_trace(go.Scattergl(name="price"), hf_x=ts, hf_y=price) # 100M+ điểm
fig.show_dash()
Quy tắc ngón tay cái: biểu đồ phân tán/heatmap dày đặc với hàng triệu điểm → Datashader; chuỗi thời gian tương tác dài → plotly-resampler.
Vẽ biểu đồ dữ liệu thị trường: biểu đồ nến và OHLC
Với một quy trình làm việc hướng tới giao dịch, lựa chọn nổi bật là mplfinance — gói vẽ biểu đồ tài chính của tổ chức Matplotlib. Nó nhận một pandas DataFrame với một DatetimeIndex và các cột Open/High/Low/Close rồi vẽ biểu đồ nến, OHLC, đường, Renko và Point & Figure, với đường trung bình động và khối lượng được tích hợp sẵn:
import mplfinance as mpf
mpf.plot(df, type="candle", mav=(20, 50), volume=True, style="charles")
Ngoài mplfinance:
- Biểu đồ nến tương tác:
go.Candlestickcủa Plotly, được bọc trongplotly-resamplermột khi lịch sử của bạn dài ra. - Biểu đồ trực tiếp/luồng: mô hình server của Bokeh, hoặc các wrapper chuyên dụng như
lightweight-charts-python(một binding cho lightweight-charts của TradingView) khi bạn muốn đúng cái giao diện của terminal giao dịch đó. - Báo cáo tĩnh/backtest: mplfinance xuất thẳng ra PNG.
So sánh tổng quan
| Thư viện | Loại | Giấy phép | Tương tác | Phù hợp nhất cho | Cần lưu ý |
|---|---|---|---|---|---|
| Matplotlib | Tĩnh | PSF/tương thích BSD | Không | Toàn quyền kiểm soát, in/PDF | Dài dòng, mặc định lỗi thời |
| Seaborn | Tĩnh | BSD-3 | Không | EDA thống kê | Phải quay về Matplotlib cho thứ bất thường |
| Plotly | Tương tác | MIT | Có | Dashboard, biểu đồ tài chính | Gói nặng; trần WebGL khoảng 1 triệu điểm |
| Bokeh | Tương tác | BSD-3 | Có | Dữ liệu luồng / ứng dụng dữ liệu | Không tự động nhanh trên dữ liệu lớn |
| Altair | Tương tác | BSD-3 | Có | Đặc tả khai báo, tái lập được | Giới hạn mặc định 5.000 hàng |
| Plotnine | Tĩnh | MIT | Không | Quen tay với ggplot2 | Chỉ tĩnh |
| Pygal | SVG | Mã nguồn mở (LGPL) | Nhẹ | Biểu đồ vector sạch trên web | Ngách; không dành cho dữ liệu lớn |
| Datashader | Raster phía server | BSD-3 | Qua HoloViews | 10⁶–10⁹ điểm | Là một ảnh, không phải dấu vẽ vector |
| mplfinance | Tĩnh | Kiểu BSD (tổ chức mpl) | Không | Biểu đồ nến / OHLC | Tĩnh; ghép với Plotly để có tương tác |
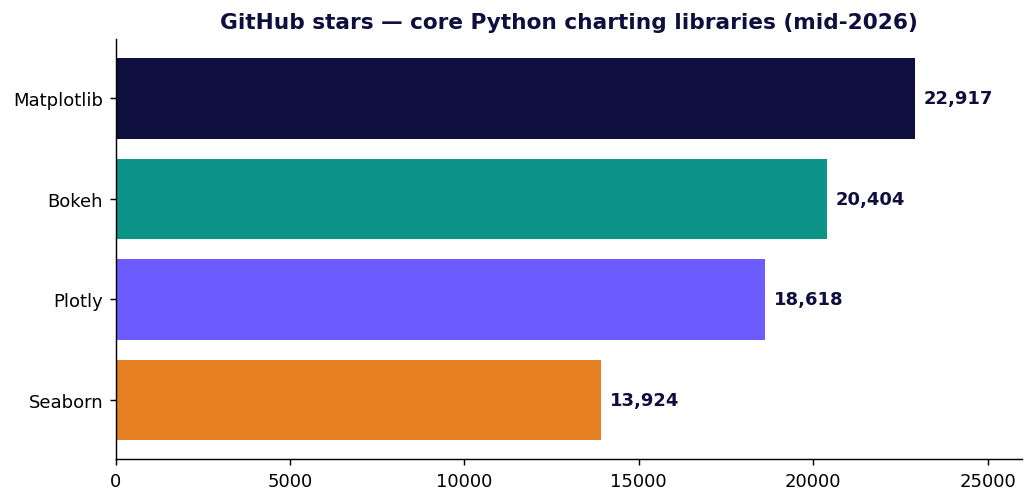
Số liệu độ phổ biến được xác minh giữa năm 2026: Plotly ≈18,6k sao / ≈1,24 tỷ lượt tải; Bokeh ≈20,4k sao / 4,3k fork. Số sao và số lượt tải thay đổi liên tục — hãy coi chúng là ảnh chụp tại một thời điểm, và nhớ rằng lượt tải PyPI thô bao gồm cả CI và mirror, nên chúng thổi phồng mức độ áp dụng thực sự của con người.
Cách chọn, gói gọn trong một hơi thở
- Biểu đồ tĩnh nhanh trong notebook → Matplotlib.
- EDA thống kê trên một DataFrame → Seaborn.
- Biểu đồ tương tác hoặc một dashboard → Plotly (hoặc Bokeh nếu là dữ liệu luồng / dạng ứng dụng).
- Đặc tả ngắn gọn, quản lý được phiên bản → Altair (để ý giới hạn 5k hàng).
- Bạn tư duy theo ggplot2 → Plotnine.
- SVG sạch cho một trang web hoặc báo cáo → Pygal.
- Hàng triệu đến hàng tỷ điểm → Datashader (dày đặc) hoặc plotly-resampler (chuỗi thời gian dài).
- Biểu đồ nến và dữ liệu thị trường → mplfinance cho tĩnh, Plotly cho tương tác.
Hãy chọn cái phù hợp với công việc, không phải cái có nhiều sao nhất. Hầu hết các dự án thực tế đều dùng kết hợp hai hoặc ba thư viện này với nhau — Seaborn để khám phá, Plotly cho dashboard, mplfinance cho báo cáo backtest — và đó là kết quả đúng đắn, không phải là một thất bại trong việc chuẩn hóa.
Phương pháp luận: các luận điểm trong bài đánh giá này đã được đối chiếu chéo với các nguồn gốc (repo GitHub của dự án, PyPI, và tài liệu chính thức) và được kiểm chứng theo lối phản biện; các con số là ảnh chụp tại thời điểm giữa năm 2026. Các con số hiệu năng được ghi là số liệu của nhà cung cấp (một tỷ điểm của Datashader, 110 triệu của plotly-resampler) là những trường hợp tốt nhất có thể tái lập, không phải là các benchmark độc lập.