ไม่มีไลบรารีสร้างกราฟ Python ตัวไหนที่ "ดีที่สุด" เพียงตัวเดียว และใครก็ตามที่บอกคุณเป็นอย่างอื่นล้วนกำลังขายของบางอย่างอยู่ คำตอบที่ซื่อตรงคือ วงการนี้แตกออกเป็นเครื่องมือกลุ่มเล็กๆ ที่แต่ละตัวชนะในงานเฉพาะของมัน ไม่ว่าจะเป็นกราฟภาพนิ่งคุณภาพระดับตีพิมพ์ กราฟสถิติแบบบรรทัดเดียว แดชบอร์ดแบบโต้ตอบได้ สเปกแบบ declarative ที่นำไปจัดการเวอร์ชันได้ หรือกราฟที่ต้องเอาตัวรอดจากข้อมูลร้อยล้านจุด รีวิวนี้จะพาเดินผ่านไลบรารีที่สำคัญ ว่าแต่ละตัวเก่งอะไรจริงๆ ตรงไหนที่มันพัง และ — เพราะเว็บนี้เน้นเรื่องการสร้างด้วย Python สำหรับตลาดการเงิน — แต่ละตัวรับมือกับกราฟแท่งเทียนและข้อมูลอนุกรมเวลาขนาดใหญ่ได้อย่างไร
ทุกตัวเลขจำนวนดาว ยอดดาวน์โหลด และไลเซนส์ด้านล่างนี้ถูกตรวจสอบกับแหล่งข้อมูลปฐมภูมิ (GitHub, PyPI, เอกสารทางการ) ในช่วงกลางปี 2026 ส่วนตรงไหนที่ตัวเลขเป็นค่ากรณีดีที่สุดที่ผู้ผลิตรายงานเอง จะมีการระบุกำกับไว้
โมเดลความคิด: ภาพนิ่ง vs แบบโต้ตอบได้
ทางแยกแรกคือ ผลลัพธ์เป็นภาพนิ่ง (PNG/SVG/PDF เรนเดอร์ครั้งเดียว) หรือเป็นกราฟแบบโต้ตอบได้ (HTML/JS เลื่อน-ซูม-ชี้ดูในเบราว์เซอร์)
- ภาพนิ่ง: Matplotlib, Seaborn, Plotnine — และ Pygal ที่ให้ผลลัพธ์เป็น SVG ซึ่งโต้ตอบได้บ้างเล็กน้อย
- โต้ตอบได้: Plotly, Bokeh, Altair
ทางแยกที่สอง — ซึ่งจะมาเล่นงานก็ต่อเมื่อข้อมูลของคุณเริ่มใหญ่ — คือ จุดข้อมูลถูกวาดที่ไหน: ในเบราว์เซอร์ (ฝั่งไคลเอนต์ ผ่าน WebGL) หรือถูกรวมยอดล่วงหน้าบนเซิร์ฟเวอร์ให้กลายเป็นรูปภาพ ความแตกต่างตรงนี้คือเนื้อเรื่องทั้งหมดของ "กลุ่มสำหรับงานสเกลใหญ่" ที่จะกล่าวถึงต่อไป และเป็นจุดที่รีวิวส่วนใหญ่มักข้ามไป
Matplotlib — รากฐานที่ทุกอย่างยืนอยู่บนมัน
Matplotlib คือพื้นฐานหลักของการพล็อตกราฟใน Python มันไม่ได้เป็นแค่ไลบรารี แต่เป็นเอนจินเรนเดอร์ที่ Seaborn, ค่าเริ่มต้นของ Plotnine, mplfinance และอีกนับสิบตัวต่อยอดขึ้นมา ไลเซนส์ของมันยืดหยุ่นมาก — ทางการระบุว่า "อ้างอิงจากไลเซนส์ PSF" และเข้ากันได้กับ BSD ดังนั้นคุณสามารถนำไปใส่ในผลิตภัณฑ์เชิงพาณิชย์แล้วขายได้โดยไม่ต้องคิดมาก (เอกสารไลเซนส์)
จุดแข็ง ควบคุมได้เบ็ดเสร็จ ถ้าคุณอธิบายมาร์กบนผืนผ้าใบ 2 มิติได้ Matplotlib ก็วาดมันได้ และมันส่งออกไฟล์เวกเตอร์ PDF/SVG ที่คมชัดสำหรับงานพิมพ์ มันถูกติดตั้งไว้ทุกที่ และทุกข้อผิดพลาดที่คุณจะเจอ ล้วนมีคำตอบบน Stack Overflow อยู่แล้ว
จุดอ่อน API ของมันขึ้นชื่อเรื่องการมีสองหัว — อินเทอร์เฟซ pyplot แบบ stateful สไตล์ MATLAB กับอินเทอร์เฟซเชิงวัตถุแบบ Figure/Axes — และบทเรียนต่างๆ ก็ผสมทั้งสองแบบเข้าด้วยกันอย่างอิสระ ซึ่งนี่แหละคือเหตุผลที่ "why you hate matplotlib" กลายเป็นหมวดเนื้อหายอดนิยม ค่าเริ่มต้นต่างๆ ก็ดูเก่า และการแต่งกราฟให้ดูทันสมัยต้องใช้โค้ดหลายบรรทัดจริงๆ
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(df.index, df["close"], lw=1.2)
ax.set_title("BTC-USD daily close")
fig.savefig("btc.png", dpi=150, bbox_inches="tight")
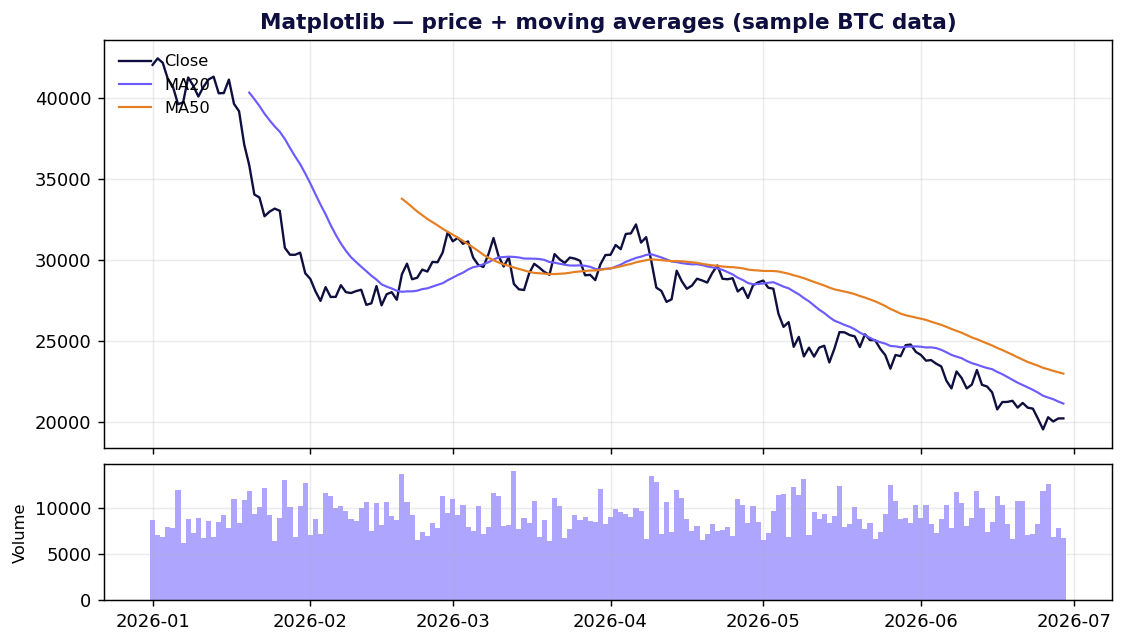
ใช้มันเมื่อ คุณต้องการกราฟภาพนิ่งที่พร้อมพิมพ์ หรือคุณกำลังสร้างเครื่องมือระดับสูงกว่าและต้องการผืนผ้าใบที่คุณควบคุมได้เต็มที่
Seaborn — กราฟสถิติโดยไม่ต้องเขียนซ้ำซาก
Seaborn เป็นเลเยอร์บางๆ ที่มีจุดยืนชัดเจนวางทับบน Matplotlib (BSD-3-Clause) ที่เปลี่ยนการจัดการแกนสิบบรรทัดให้เหลือบรรทัดเดียว มัน "ให้อินเทอร์เฟซระดับสูงสำหรับการวาดกราฟสถิติที่สวยงาม" และผสานรวมกับ pandas อย่างแน่นแฟ้น — การกระจายตัว การถดถอย ฮีตแมป และ small-multiples แบบแบ่งช่อง ล้วนเรียกใช้ได้ด้วยคำสั่งเดียว
import seaborn as sns
sns.set_theme()
sns.lineplot(data=returns, x="date", y="ret", hue="symbol")
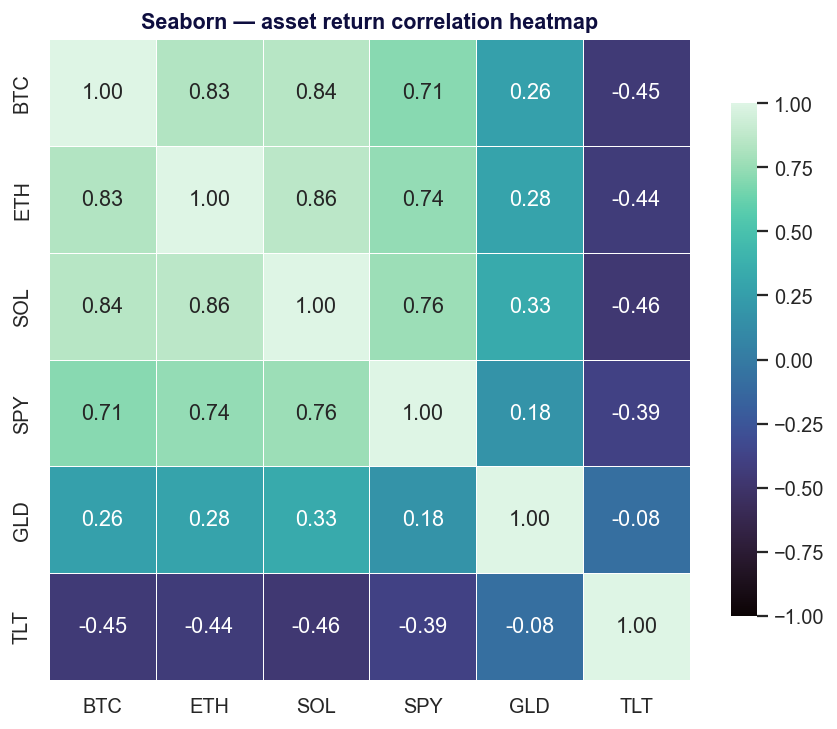
จุดแข็ง ค่าเริ่มต้นทางสถิติระดับท็อป สวยงามตั้งแต่แกะกล่อง เป็นตัวเลือกแรกที่ชัดเจนสำหรับการสำรวจข้อมูลเบื้องต้น (EDA)
จุดอ่อน มันรับมรดกความเป็นภาพนิ่งของ Matplotlib มา (ไม่มีการโต้ตอบ) และเมื่อคุณต้องการกราฟที่มันไม่มีฟังก์ชันรองรับ คุณก็ต้องตกกลับลงไปเขียน Matplotlib ดิบๆ อยู่ดี มันเป็นเลเยอร์อำนวยความสะดวก ไม่ใช่ทางหนีจากตัวเอนจิน
ใช้มันเมื่อ คุณกำลังทำ EDA บน DataFrame และอยากได้ฮีตแมปสหสัมพันธ์ กราฟการกระจายตัว หรือกราฟการถดถอยอย่างรวดเร็ว
Plotly — ตัวเลือกแบบโต้ตอบได้ที่เป็นค่าเริ่มต้น
Plotly.py เป็นตัวเลือกแบบโต้ตอบได้ที่ถูกนำมาใช้แพร่หลายที่สุด มันใช้ไลเซนส์ MIT สร้างขึ้นบน plotly.js และตัวเลขก็ทิ้งห่างคู่แข่งไม่ใกล้เลย: ราว 18.6k ดาวบน GitHub และยอดดาวน์โหลดสะสมตลอดกาลบน PyPI ราว 1.24 พันล้านครั้ง — ประมาณ 61 ล้านครั้งในช่วง 30 วันที่ผ่านมา (PyPI · สถิติดาวน์โหลด) ทูลทิปเมื่อชี้ดู การซูม การเลื่อน และการสลับเปิด-ปิดในเลเจนด์ มาให้ฟรี และกราฟตัวเดียวกันก็เรนเดอร์ได้ทั้งในโน้ตบุ๊ก ในแอป Dash หรือไฟล์ HTML ภาพนิ่ง
import plotly.graph_objects as go
fig = go.Figure(go.Candlestick(
x=df.index, open=df.open, high=df.high, low=df.low, close=df.close,
))
fig.update_layout(title="BTC-USDT", xaxis_rangeslider_visible=False)
fig.show()
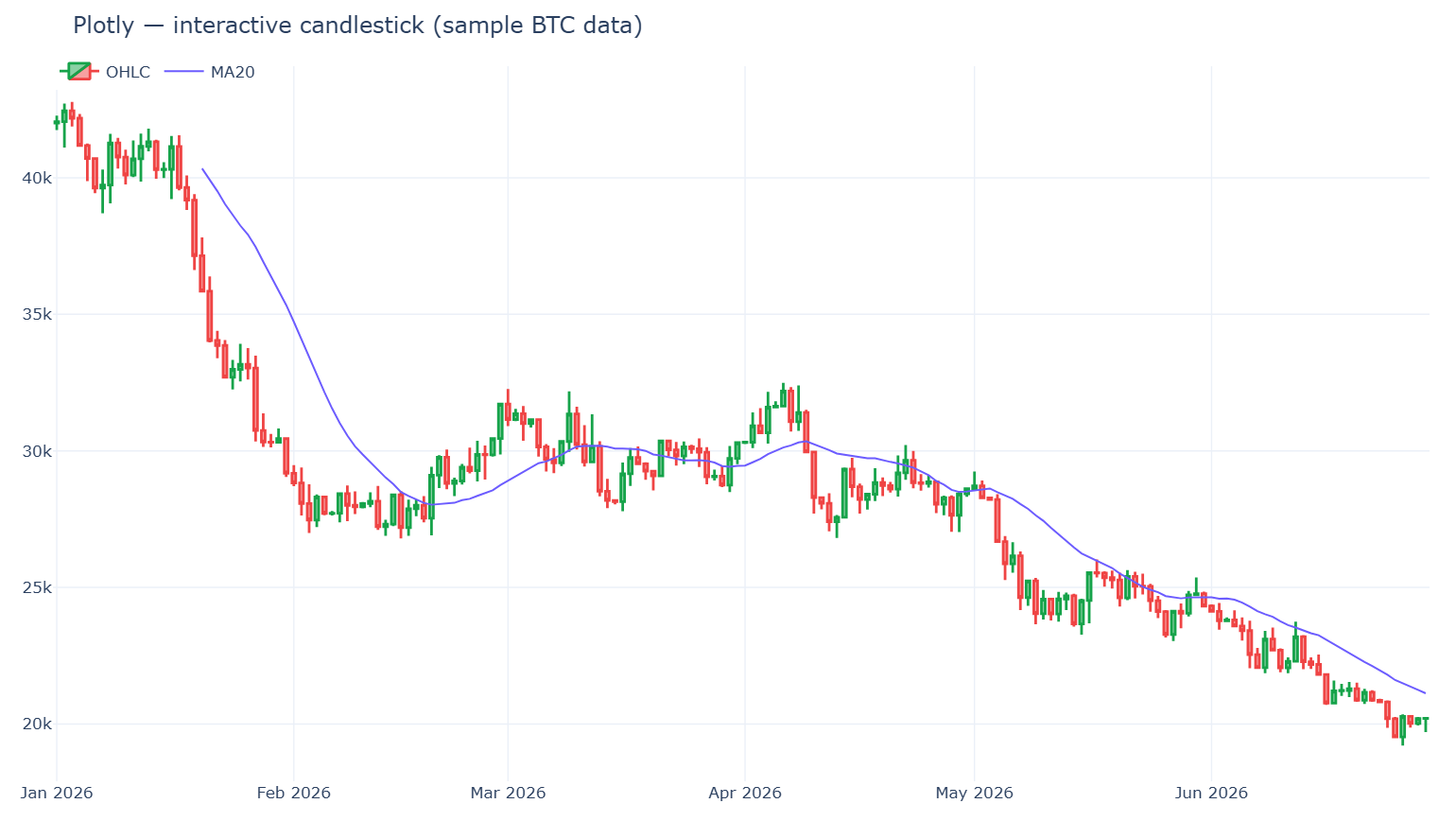
จุดแข็ง การโต้ตอบได้โดยไม่ต้องเขียน JavaScript เลย ประเภทกราฟการเงินระดับเฟิร์สคลาส (go.Candlestick, go.Ohlc) เส้นทางสู่แดชบอร์ดเต็มรูปแบบ (Dash) ก็สั้น
จุดอ่อน บันเดิล plotly.js หนัก — เป็นต้นทุนจริงสำหรับเว็บไซต์ที่ไวต่อเวลาโหลดหน้า (การวิเคราะห์เวลาบันเดิล) และมีเพดานการเรนเดอร์ที่ตายตัว: ด้วยเทรซแบบ WebGL (go.Scattergl) คุณแสดงได้ถึงราว 1 ล้านจุด แต่เบราว์เซอร์อนุญาตเพียง 8–16 WebGL context ต่อหน้า ดังนั้นในทางปฏิบัติคุณได้ 4–8 กราฟ WebGL ก่อนจะชน "Too many active WebGL contexts" (เอกสารประสิทธิภาพของ Plotly) การซูม/เลื่อนแบบโต้ตอบที่ลื่นไหลตามจริงรองรับได้ราว 100–200k จุด
ใช้มันเมื่อ คุณต้องการกราฟหรือแดชบอร์ดแบบโต้ตอบได้ โดยเฉพาะกราฟการเงิน และอนุกรมข้อมูลของคุณอยู่ในระดับหลักพันถึงหลักล้านต้นๆ
Bokeh — แบบโต้ตอบได้ที่สร้างมาเพื่อข้อมูลขนาดใหญ่และสตรีมมิง
Bokeh (BSD-3-Clause, ราว 20.4k ดาว / 4.3k forks) เป็นคู่แข่งหลักแบบโต้ตอบได้ของ Plotly ที่มีจุดศูนย์ถ่วงต่างออกไป: มันคือ "ไลบรารีการสร้างภาพแบบโต้ตอบได้สำหรับเว็บเบราว์เซอร์สมัยใหม่" ที่มุ่งไปที่ชุดข้อมูลขนาดใหญ่และสตรีมมิง และแอปที่ขับเคลื่อนด้วยเซิร์ฟเวอร์ (เซิร์ฟเวอร์ Bokeh สามารถผลักอัปเดตสดไปยังกราฟผ่าน websocket ได้)
ข้อแม้ที่ซื่อตรงข้อหนึ่งซึ่งฝ่ายการตลาดจะไม่บอกคุณ: คำว่า "ประสิทธิภาพสูง" เป็นการอธิบายตัวเองส่วนหนึ่ง รายงานจากการใช้งานจริงแสดงให้เห็นว่าการชี้ดู/ทูลทิปเริ่มอืดบนชุดข้อมูลเล็กเพียงราว 50k จุด ดังนั้นมันจึงไม่ได้เร็วโดยอัตโนมัติบนข้อมูลขนาดมหึมา — คุณยังต้องหันไปพึ่งการรวมยอด (ดูด้านล่าง) ให้มองจุดเด่นของ Bokeh ว่าอยู่ที่ สตรีมมิงและสถาปัตยกรรมแอป ไม่ใช่จำนวนจุดข้อมูลดิบ
from bokeh.plotting import figure, show
p = figure(x_axis_type="datetime", title="BTC-USD", height=350)
p.line(df["date"], df["close"])
show(p)
ใช้มันเมื่อ คุณกำลังสร้างแดชบอร์ดที่อัปเดตสด หรือแอปข้อมูลที่ขับเคลื่อนด้วย Python และต้องการการควบคุมการโต้ตอบฝั่งเซิร์ฟเวอร์
Altair — ไวยากรณ์กราฟิกแบบ declarative
Altair เป็นไลบรารีแบบ declarative: คุณอธิบายว่าจะเข้ารหัสอะไร (คอลัมน์นี้ไปแกน x คอลัมน์นั้นไปเป็นสี) แล้วเอนจิน Vega-Lite จะตัดสินใจว่าจะวาดอย่างไร กราฟเป็นสเปก JSON ซึ่งทำให้ประกอบรวมกันได้และเทียบความต่าง (diff) ได้ง่าย
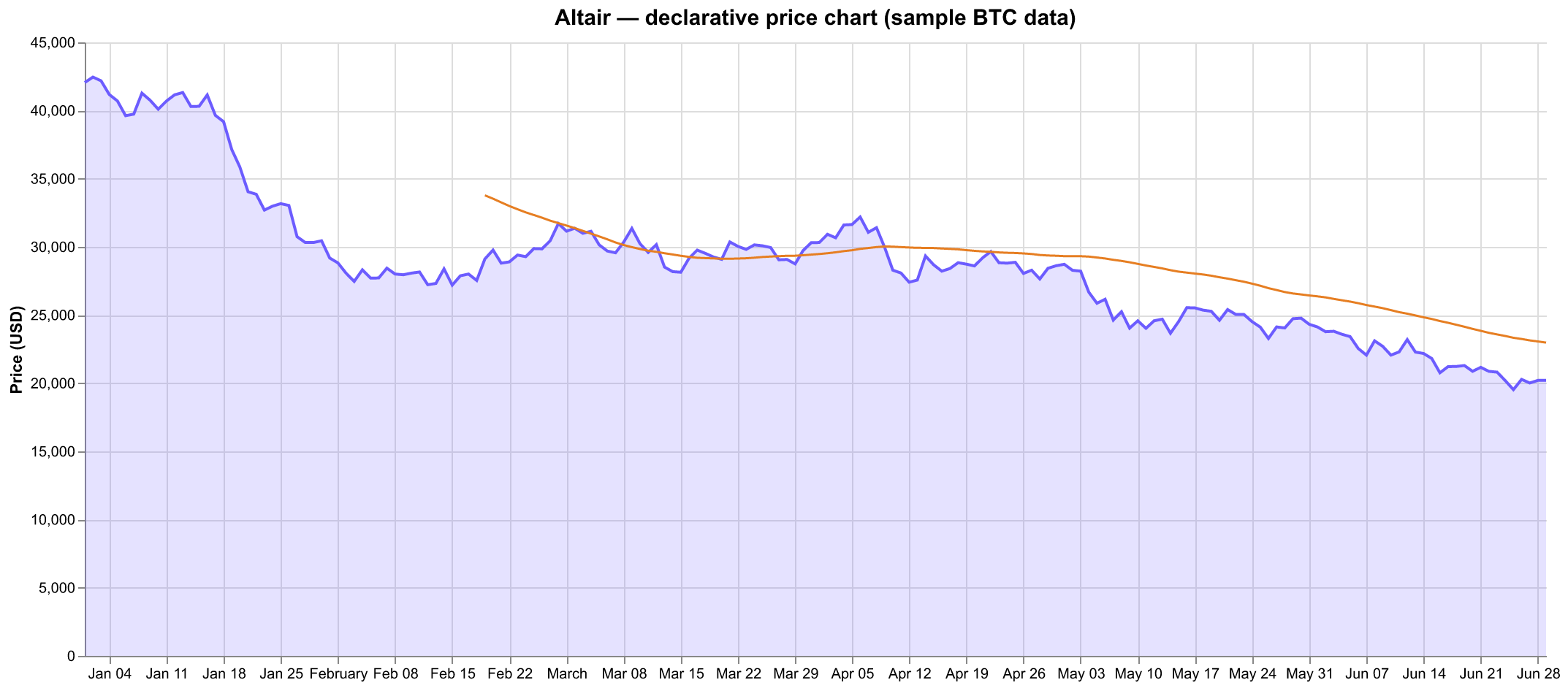
กับดักที่มือใหม่ทุกคนเจอ: โดยค่าเริ่มต้น Altair ปฏิเสธที่จะพล็อตข้อมูลเกิน 5,000 แถว โดยจะโยน MaxRowsError ออกมา มันเป็นราวกั้นที่ตั้งใจวางไว้ (Altair ฝังข้อมูลเป็น JSON ลงในสเปก) ไม่ใช่ความไม่สามารถจัดการข้อมูลได้ — และยกราวกั้นนี้ออกได้ด้วยโค้ดบรรทัดเดียว:
import altair as alt
alt.data_transformers.disable_max_rows() # or use the VegaFusion backend for ~100k+
alt.Chart(df).mark_line().encode(x="date:T", y="close:Q")
มันเป็นแหล่งความหงุดหงิดที่เกิดซ้ำๆ ก็เพราะข้อผิดพลาดนี้โผล่ขึ้นมาในเฟรมที่รู้สึกเหมือน "เล็ก" ขนาด 35k แถว (เอกสารชุดข้อมูลขนาดใหญ่)
ใช้มันเมื่อ คุณให้คุณค่ากับสเปกกราฟที่กระชับ เป็น declarative และทำซ้ำได้ และข้อมูลของคุณมีขนาดพอประมาณ — หรือคุณยินดีต่อ VegaFusion เข้าไปสำหรับเฟรมที่ใหญ่ขึ้น
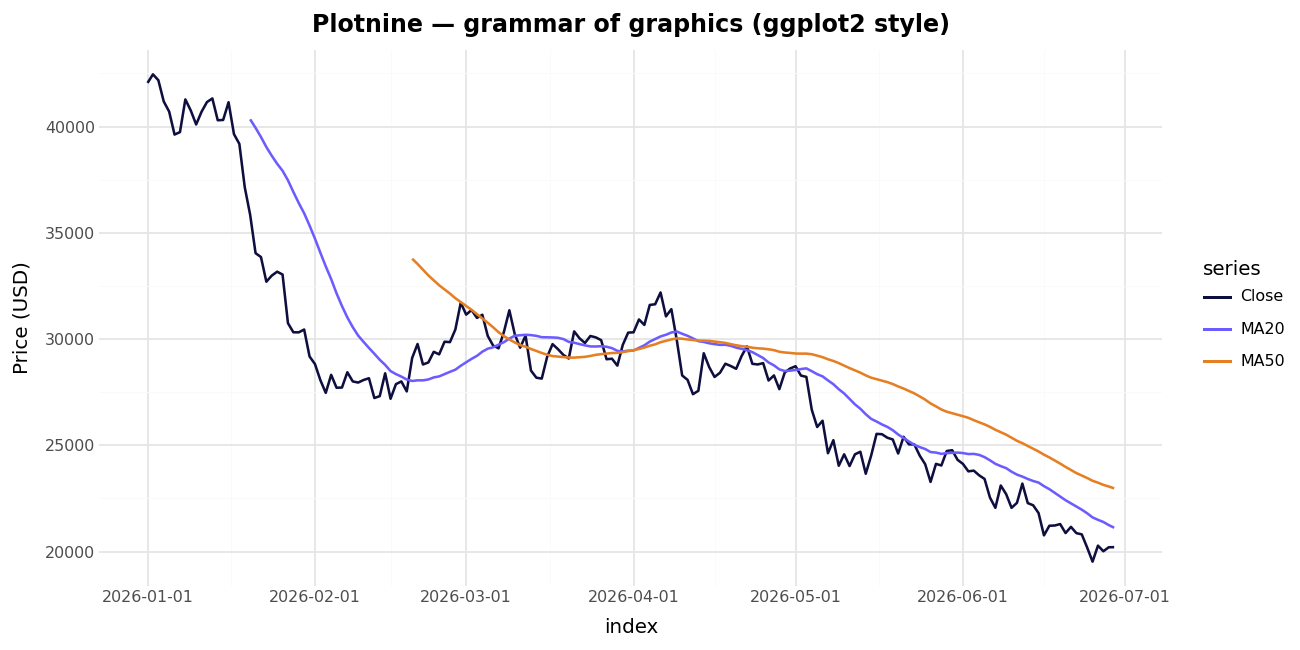
Plotnine และ Pygal — เติมเต็มสนามให้ครบ
- Plotnine เป็นการพอร์ตไวยากรณ์กราฟิก
ggplot2ของ R มาแบบเกือบตรงเป๊ะ (ไลเซนส์ MIT) ถ้าคุณมาจากสาย R หรือคิดในแบบaes()+geom_*แบบเป็นเลเยอร์ นี่คือ API ที่เป็นธรรมชาติที่สุดในลิสต์นี้ มันเรนเดอร์ผ่าน Matplotlib จึงเป็นภาพนิ่ง
python
from plotnine import ggplot, aes, geom_line
(ggplot(df, aes("date", "close")) + geom_line())
- Pygal ให้ผลลัพธ์เป็นกราฟ SVG — ไม่ขึ้นกับความละเอียด แต่งสไตล์ด้วย CSS ได้ และฝังในรายงานหรือหน้าเว็บได้เล็กกระทัดรัด มันเป็นตัวเลือกเฉพาะกลุ่ม: น่ารักสำหรับกราฟเวกเตอร์สะอาดตาบนหน้าเว็บ ไม่ได้สร้างมาเพื่อข้อมูลขนาดใหญ่หรือการโต้ตอบหนักๆ
เมื่อข้อมูลของคุณใหญ่ขึ้น: กลุ่มสำหรับงานสเกลใหญ่
นี่คือจุดที่ตัวเลือกแบบไร้เดียงสาล้มไม่เป็นท่า เมื่อคุณเลยหลักล้านจุดไปแล้ว คุณจะส่งมันให้เบราว์เซอร์ตรงๆ ไม่ได้ (ขอพูดให้ชัดเรื่องความเชื่อผิดๆ ข้อหนึ่ง: เบราว์เซอร์สามารถแสดงจุด WebGL ราว 1 ล้านจุดได้ — สิ่งที่เสื่อมลงคือความลื่นไหลในการโต้ตอบ ไม่ใช่การพังแบบฮาร์ดแครช) มีสองกลยุทธ์ที่แก้ปัญหานี้:
1. การแรสเตอร์ฝั่งเซิร์ฟเวอร์ — Datashader แทนที่จะส่งจุดไปยังเบราว์เซอร์ Datashader (BSD-3-Clause) จัดจุดเหล่านั้นลงในตาราง 2 มิติขนาดคงที่ แล้วเรนเดอร์ตารางนั้นออกมาเป็นรูปภาพ "โดยรักษาการกระจายตัวของข้อมูลไว้อย่างซื่อตรง" ตัวเลขพาดหัวของมัน: พันล้านจุดในเวลาราวหนึ่งวินาทีบนแล็ปท็อป 16 GB ขยายแบบ out-of-core และไปยัง GPU ได้ผ่าน Dask (บทนำ · คู่มือข้อมูลขนาดใหญ่ของ HoloViews) ให้มองตัวเลขพันล้านจุดต่อวินาทีว่าเป็นกรณีดีที่สุดที่ผู้ผลิตอ้าง — แต่แนวทางของมัน (จัดตารางใหม่ทุกครั้งที่ซูม/เลื่อน) เป็นแนวทางที่ถูกต้องอย่างแท้จริงสำหรับข้อมูลหนาแน่น
import datashader as ds, datashader.transfer_functions as tf
cvs = ds.Canvas(plot_width=900, plot_height=400)
agg = cvs.points(df, "t", "price") # df can be a Dask frame larger than RAM
img = tf.shade(agg)
2. การลดตัวอย่างตามมุมมอง — plotly-resampler ตัวนี้คงความสามารถโต้ตอบเต็มรูปแบบของ Plotly ไว้ แต่จะเรนเดอร์เฉพาะจุดที่คุณมองเห็นได้จริงเท่านั้น การรวมยอดแบบ MinMaxLTTB ที่เป็นค่าเริ่มต้นของมันจะลดแต่ละเทรซเหลือราว 1,000 จุดที่พล็อตสำหรับมุมมองปัจจุบัน แล้วดึงข้อมูลใหม่เมื่อคุณซูม — เดโมแสดงข้อมูลกว่า 110 ล้านจุดด้วยวิธีนี้ (เปเปอร์)
from plotly_resampler import FigureResampler
import plotly.graph_objects as go
fig = FigureResampler(go.Figure())
fig.add_trace(go.Scattergl(name="price"), hf_x=ts, hf_y=price) # 100M+ points
fig.show_dash()
หลักการง่ายๆ: กราฟกระจาย/ฮีตแมปหนาแน่นระดับหลายล้านจุด → Datashader; อนุกรมเวลาแบบโต้ตอบที่ยาว → plotly-resampler
การสร้างกราฟข้อมูลตลาด: แท่งเทียนและ OHLC
สำหรับเวิร์กโฟลว์ที่เน้นการเทรด ตัวที่โดดเด่นคือ mplfinance — แพ็กเกจสร้างกราฟการเงินจากองค์กร Matplotlib มันรับ pandas DataFrame ที่มี DatetimeIndex และคอลัมน์ Open/High/Low/Close แล้ววาดกราฟแท่งเทียน OHLC เส้น Renko และ Point & Figure พร้อมเส้นค่าเฉลี่ยเคลื่อนที่และปริมาณการซื้อขายในตัว:
import mplfinance as mpf
mpf.plot(df, type="candle", mav=(20, 50), volume=True, style="charles")
นอกเหนือจาก mplfinance:
- แท่งเทียนแบบโต้ตอบได้:
go.Candlestickของ Plotly ห่อด้วยplotly-resamplerเมื่อประวัติข้อมูลของคุณยาวขึ้น - กราฟสด/สตรีมมิง: โมเดลเซิร์ฟเวอร์ของ Bokeh หรือ wrapper เฉพาะทางอย่าง
lightweight-charts-python(ตัวเชื่อมต่อ lightweight-charts ของ TradingView) เมื่อคุณต้องการลุคแบบเทอร์มินัลเทรดเป๊ะๆ - รายงานภาพนิ่ง/แบ็กเทสต์: mplfinance ส่งออกเป็น PNG ตรงๆ
ภาพรวมเปรียบเทียบโดยสรุป
| ไลบรารี | ประเภท | ไลเซนส์ | โต้ตอบได้ | เหมาะกับ | ข้อควรระวัง |
|---|---|---|---|---|---|
| Matplotlib | ภาพนิ่ง | PSF/เข้ากันได้กับ BSD | ไม่ | ควบคุมเต็มที่, งานพิมพ์/PDF | เขียนเยอะ, ค่าเริ่มต้นดูเก่า |
| Seaborn | ภาพนิ่ง | BSD-3 | ไม่ | EDA เชิงสถิติ | ตกกลับไป Matplotlib สำหรับเคสแปลกๆ |
| Plotly | โต้ตอบได้ | MIT | ใช่ | แดชบอร์ด, กราฟการเงิน | บันเดิลหนัก; เพดาน WebGL ราว 1M จุด |
| Bokeh | โต้ตอบได้ | BSD-3 | ใช่ | สตรีมมิง / แอปข้อมูล | ไม่ได้เร็วอัตโนมัติบนข้อมูลใหญ่ |
| Altair | โต้ตอบได้ | BSD-3 | ใช่ | สเปกแบบ declarative ทำซ้ำได้ | เพดานค่าเริ่มต้น 5,000 แถว |
| Plotnine | ภาพนิ่ง | MIT | ไม่ | กล้ามเนื้อความจำสาย ggplot2 | ภาพนิ่งเท่านั้น |
| Pygal | SVG | โอเพนซอร์ส (LGPL) | เล็กน้อย | กราฟเวกเตอร์สะอาดตาบนเว็บ | เฉพาะกลุ่ม; ไม่เหมาะข้อมูลใหญ่ |
| Datashader | แรสเตอร์ฝั่งเซิร์ฟเวอร์ | BSD-3 | ผ่าน HoloViews | 10⁶–10⁹ จุด | เป็นรูปภาพ ไม่ใช่มาร์กเวกเตอร์ |
| mplfinance | ภาพนิ่ง | สไตล์ BSD (องค์กร mpl) | ไม่ | แท่งเทียน / OHLC | ภาพนิ่ง; จับคู่กับ Plotly เพื่อการโต้ตอบ |
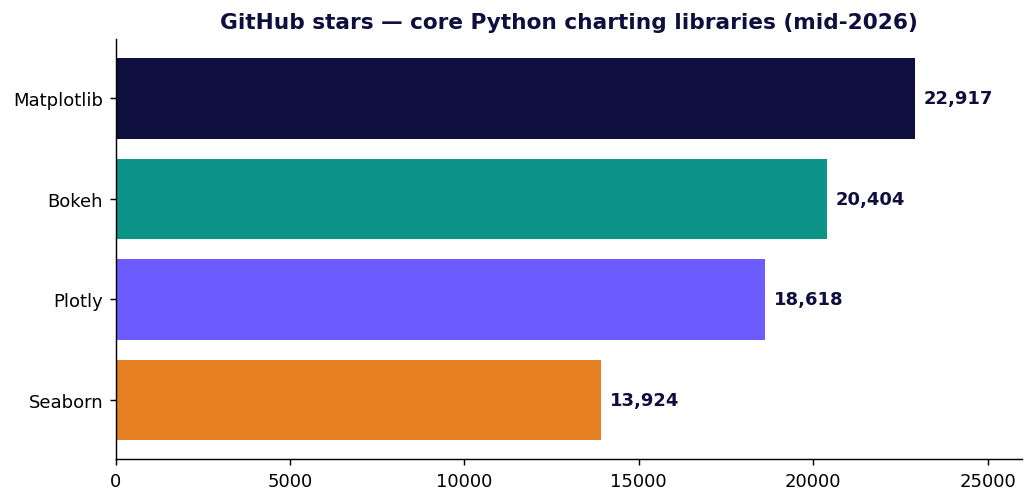
ตัวเลขความนิยมตรวจสอบเมื่อกลางปี 2026: Plotly ราว 18.6k ดาว / ราว 1.24B ดาวน์โหลด; Bokeh ราว 20.4k ดาว / 4.3k forks จำนวนดาวและยอดดาวน์โหลดเปลี่ยนแปลงตลอดเวลา — ให้มองว่าเป็นภาพสแนปช็อต และจำไว้ว่ายอดดาวน์โหลดดิบบน PyPI รวมทั้ง CI และมิเรอร์ด้วย ดังนั้นมันจึงเกินจริงไปจากการนำไปใช้ของคนจริง
วิธีเลือกแบบรวบรัดในลมหายใจเดียว
- กราฟภาพนิ่งด่วนๆ ในโน้ตบุ๊ก → Matplotlib
- EDA เชิงสถิติบน DataFrame → Seaborn
- กราฟหรือแดชบอร์ดแบบโต้ตอบได้ → Plotly (หรือ Bokeh ถ้าเป็นงานสตรีมมิง / รูปแบบแอป)
- สเปกที่กระชับและจัดการเวอร์ชันได้ → Altair (ระวังเพดาน 5k แถว)
- คุณคิดในแบบ ggplot2 → Plotnine
- SVG สะอาดตาสำหรับหน้าเว็บหรือรายงาน → Pygal
- ข้อมูลระดับล้านถึงพันล้านจุด → Datashader (หนาแน่น) หรือ plotly-resampler (อนุกรมเวลาที่ยาว)
- แท่งเทียนและข้อมูลตลาด → mplfinance สำหรับภาพนิ่ง, Plotly สำหรับแบบโต้ตอบ
เลือกตัวที่ตรงกับงาน ไม่ใช่ตัวที่มีดาวเยอะที่สุด โปรเจกต์จริงส่วนใหญ่ลงเอยด้วยการใช้สองหรือสามตัวนี้ร่วมกัน — Seaborn สำหรับการสำรวจ, Plotly สำหรับแดชบอร์ด, mplfinance สำหรับรายงานแบ็กเทสต์ — และนั่นคือผลลัพธ์ที่ถูกต้อง ไม่ใช่ความล้มเหลวในการทำให้เป็นมาตรฐานเดียวกัน
ระเบียบวิธี: ข้อกล่าวอ้างในรีวิวนี้ถูกตรวจสอบทานกับแหล่งข้อมูลปฐมภูมิ (รีโป GitHub ของโปรเจกต์, PyPI และเอกสารทางการ) และยืนยันแบบ adversarial; ตัวเลขเป็นสแนปช็อต ณ กลางปี 2026 ตัวเลขประสิทธิภาพที่ระบุว่าเป็นตัวเลขของผู้ผลิต (พันล้านจุดของ Datashader, 110M ของ plotly-resampler) เป็นกรณีดีที่สุดที่ทำซ้ำได้ ไม่ใช่เบนช์มาร์กอิสระ