Il n'existe pas de « meilleure » bibliothèque de charting Python unique, et quiconque vous affirme le contraire a quelque chose à vous vendre. La réponse honnête, c'est que le domaine se divise en une poignée d'outils qui remportent chacun une tâche précise : un graphique statique de qualité publication, une statistique en une ligne, un tableau de bord interactif, une spécification déclarative que l'on peut versionner, ou un graphique qui doit survivre à cent millions de points. Cette revue parcourt les bibliothèques qui comptent, ce dans quoi chacune excelle réellement, où chacune flanche, et — puisque ce site parle de développement en Python pour les marchés — comment elles gèrent les chandeliers et les grandes séries temporelles.
Chaque nombre d'étoiles, chaque chiffre de téléchargement et chaque licence ci-dessous ont été vérifiés par rapport aux sources primaires (GitHub, PyPI, documentation officielle) à la mi-2026. Lorsqu'un chiffre correspond au meilleur cas autodéclaré par un éditeur, il est signalé comme tel.
Le modèle mental : statique ou interactif
La première bifurcation, c'est de savoir si la sortie est une image statique (PNG/SVG/PDF, rendue une seule fois) ou une figure interactive (HTML/JS, panoramique-zoom-survol dans un navigateur).
- Statique : Matplotlib, Seaborn, Plotnine — et Pygal, qui produit du SVG plus ou moins interactif.
- Interactif : Plotly, Bokeh, Altair.
La seconde bifurcation — qui ne mord qu'une fois vos données devenues volumineuses — c'est où les points sont dessinés : dans le navigateur (côté client, WebGL) ou pré-agrégés sur le serveur en une image. Cette distinction est toute l'histoire du « palier de montée en charge » plus bas, et c'est celle que la plupart des revues passent sous silence.
Matplotlib — le socle sur lequel tout repose
Matplotlib est le fondement du tracé en Python. Ce n'est pas seulement une bibliothèque ; c'est le moteur de rendu sur lequel Seaborn, les valeurs par défaut de Plotnine, mplfinance et une douzaine d'autres se construisent. Sa licence est permissive — officiellement « basée sur la licence PSF » et compatible BSD, vous pouvez donc l'intégrer dans un produit propriétaire et le vendre sans la moindre hésitation (documentation de licence).
Points forts. Contrôle total. Si vous pouvez décrire une marque sur un canevas 2D, Matplotlib peut la dessiner, et il exporte du PDF/SVG vectoriel net pour l'impression. Il est installé partout et la moindre erreur que vous rencontrerez a déjà sa réponse sur Stack Overflow.
Points faibles. L'API est célèbre pour sa double tête — une interface pyplot à état, façon MATLAB, et une interface orientée objet Figure/Axes — et les tutoriels les mélangent allègrement, ce qui explique précisément pourquoi « why you hate matplotlib » est devenu un genre à part entière. Les valeurs par défaut sont datées, et styliser un graphique pour qu'il ait l'air moderne demande de vraies lignes de code.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(df.index, df["close"], lw=1.2)
ax.set_title("BTC-USD daily close")
fig.savefig("btc.png", dpi=150, bbox_inches="tight")
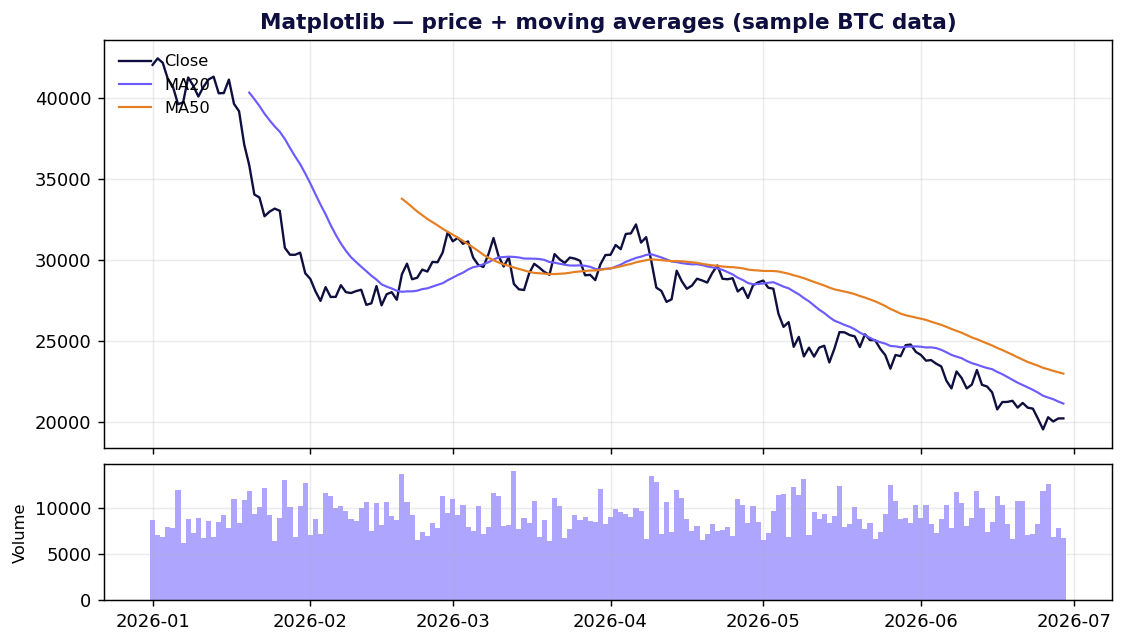
À utiliser quand vous avez besoin d'une figure statique prête à imprimer, ou que vous construisez un outil de plus haut niveau et voulez un canevas que vous maîtrisez entièrement.
Seaborn — des graphiques statistiques sans le code répétitif
Seaborn est une couche fine et tranchée par-dessus Matplotlib (BSD-3-Clause) qui transforme dix lignes de bricolage d'axes en une seule. Il « fournit une interface de haut niveau pour dessiner des graphiques statistiques attrayants » et s'intègre étroitement à pandas — distributions, régressions, cartes de chaleur et petits multiples à facettes tiennent tous en un seul appel.
import seaborn as sns
sns.set_theme()
sns.lineplot(data=returns, x="date", y="ret", hue="symbol")
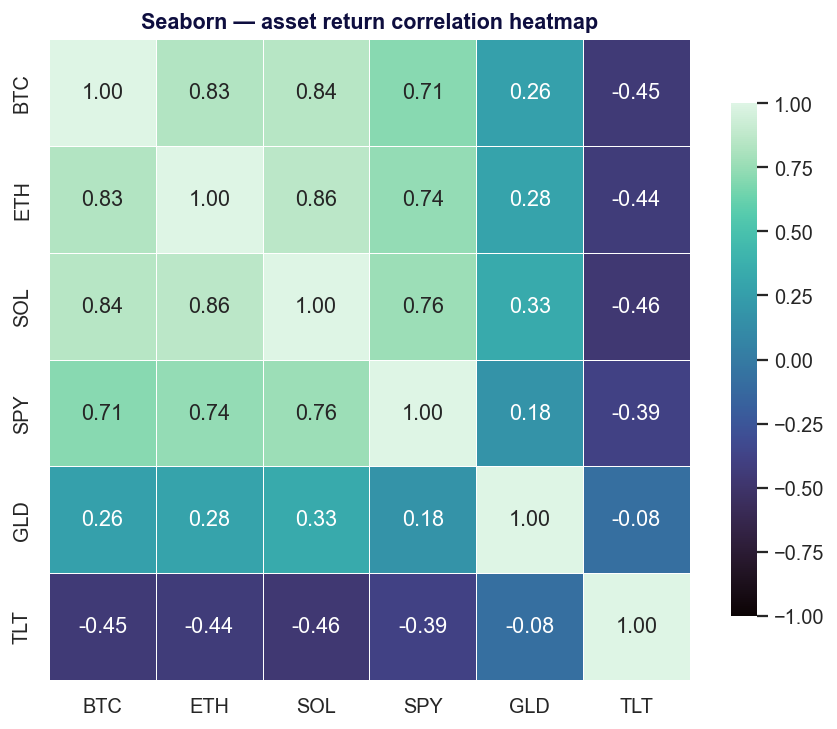
Points forts. Des valeurs par défaut statistiques au meilleur niveau ; superbe dès la sortie de la boîte ; le premier réflexe évident pour l'analyse exploratoire des données.
Points faibles. Il hérite de la nature statique de Matplotlib (aucune interactivité) et, lorsque vous avez besoin d'un graphique pour lequel il n'a pas de fonction, vous retombez de toute façon sur du Matplotlib brut. C'est une couche de confort, pas une échappatoire au moteur.
À utiliser quand vous faites de l'analyse exploratoire sur un DataFrame et voulez rapidement des cartes de chaleur de corrélation, des distributions ou des graphiques de régression.
Plotly — la valeur par défaut de l'interactif
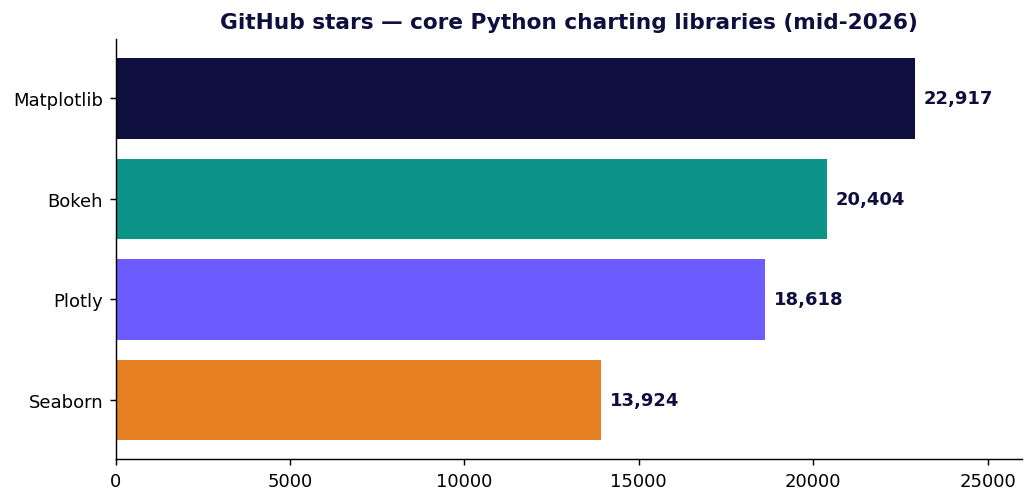
Plotly.py est l'option interactive la plus largement adoptée. Sous licence MIT, construit par-dessus plotly.js, et les chiffres ne laissent pas place au doute : environ 18,6 k étoiles GitHub et près de 1,24 milliard de téléchargements PyPI cumulés — de l'ordre de 61 millions de téléchargements sur les 30 derniers jours (PyPI · statistiques de téléchargement). Infobulles au survol, zoom, panoramique et bascule de légende sont fournis gratuitement, et la même figure se rend dans un notebook, une application Dash ou un fichier HTML statique.
import plotly.graph_objects as go
fig = go.Figure(go.Candlestick(
x=df.index, open=df.open, high=df.high, low=df.low, close=df.close,
))
fig.update_layout(title="BTC-USDT", xaxis_rangeslider_visible=False)
fig.show()
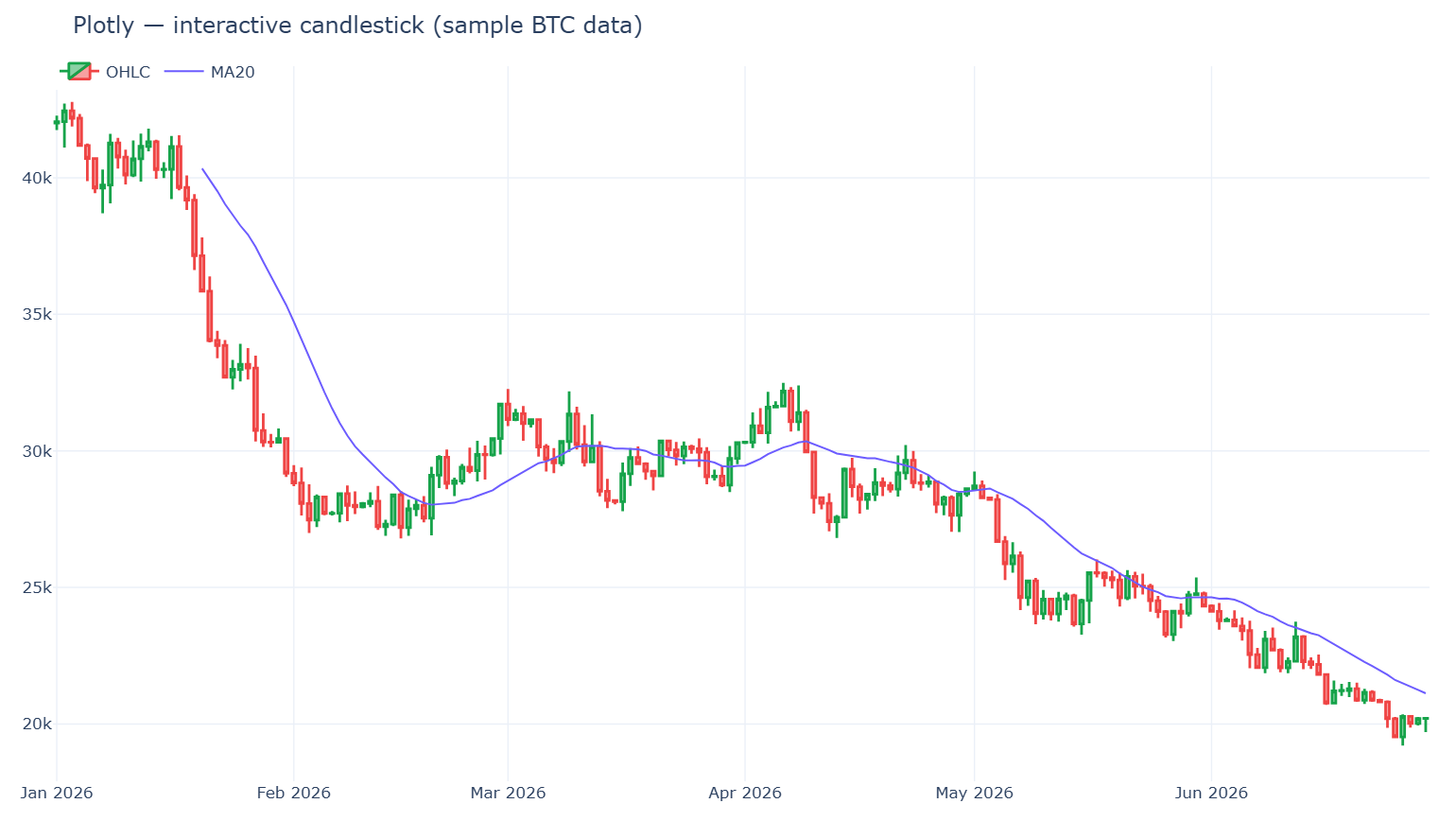
Points forts. Interactivité sans une ligne de JavaScript ; des types de graphiques financiers de premier ordre (go.Candlestick, go.Ohlc) ; le chemin vers un tableau de bord complet (Dash) est court.
Points faibles. Le bundle plotly.js est lourd — un coût réel pour les sites sensibles au temps de chargement (analyse du temps de bundle). Et il existe un plafond de rendu dur : avec les traces WebGL (go.Scattergl) vous pouvez représenter jusqu'à ~1 million de points, mais les navigateurs n'autorisent que 8 à 16 contextes WebGL par page, si bien qu'en pratique vous obtenez 4 à 8 figures WebGL avant de heurter le message « Too many active WebGL contexts » (documentation de performance Plotly). Un zoom/panoramique interactif fluide tient de façon réaliste jusqu'à ~100–200 k points.
À utiliser quand vous voulez des graphiques ou tableaux de bord interactifs, en particulier financiers, et que vos séries comptent de quelques milliers à quelques millions de points.
Bokeh — l'interactif conçu pour les données massives et en flux
Bokeh (BSD-3-Clause, ~20,4 k étoiles / 4,3 k forks) est le principal rival interactif de Plotly, avec un centre de gravité différent : c'est « une bibliothèque de visualisation interactive pour les navigateurs web modernes » visant les jeux de données massifs et en flux ainsi que les applications pilotées par serveur (le serveur Bokeh peut pousser des mises à jour en direct vers un graphique via un websocket).
Une réserve honnête que le marketing ne vous donnera pas : la « haute performance » est en partie de l'autodescription. Des retours du terrain montrent le survol/les infobulles qui s'engluent sur des jeux de données aussi petits que ~50 k points, donc ce n'est pas automatiquement rapide sur de grosses données — il faut quand même recourir à l'agrégation (ci-dessous). Considérez l'avantage de Bokeh comme étant le flux de données et l'architecture applicative, pas le nombre brut de points.
from bokeh.plotting import figure, show
p = figure(x_axis_type="datetime", title="BTC-USD", height=350)
p.line(df["date"], df["close"])
show(p)
À utiliser quand vous construisez un tableau de bord à mise à jour en direct ou une application de données pilotée par Python et voulez un contrôle côté serveur sur l'interactivité.
Altair — une grammaire déclarative des graphiques
Altair est une bibliothèque déclarative : vous décrivez quoi encoder (cette colonne en x, celle-là en couleur) et le moteur Vega-Lite décide comment le dessiner. Les graphiques sont des spécifications JSON, ce qui les rend composables et faciles à comparer (diff).
Le piège que tout nouveau venu rencontre : par défaut, Altair refuse de tracer plus de 5 000 lignes, levant une MaxRowsError. C'est un garde-fou délibéré (Altair intègre les données sous forme de JSON dans la spécification), pas une incapacité à gérer les données — et il se lève en une ligne :
import altair as alt
alt.data_transformers.disable_max_rows() # or use the VegaFusion backend for ~100k+
alt.Chart(df).mark_line().encode(x="date:T", y="close:Q")
C'est une source récurrente de frustration précisément parce que l'erreur surgit sur ce qui ressemble à un « petit » tableau de 35 k lignes (documentation sur les grands jeux de données).
À utiliser quand vous tenez à des spécifications de graphiques concises, déclaratives et reproductibles et que vos données sont modestes — ou que vous êtes prêt à câbler VegaFusion pour les tableaux plus volumineux.
Plotnine et Pygal — pour compléter le tableau
- Plotnine est un portage quasi fidèle de la grammaire des graphiques
ggplot2de R (sous licence MIT). Si vous venez de R ou que vous pensez enaes()+geom_*en couches, c'est l'API la plus naturelle de cette liste. Il rend via Matplotlib, il est donc statique.
python
from plotnine import ggplot, aes, geom_line
(ggplot(df, aes("date", "close")) + geom_line())
- Pygal produit des graphiques SVG — indépendants de la résolution, stylisables en CSS, et minuscules à intégrer dans un rapport ou une page web. C'est un choix de niche : superbe pour des graphiques vectoriels propres sur une page web, pas conçu pour les grandes données ni l'interactivité lourde.
Quand vos données deviennent volumineuses : le palier de montée en charge
C'est là que les choix naïfs s'effondrent. Au-delà d'un million de points, vous ne pouvez pas simplement les confier au navigateur. (Pour être précis sur un mythe : les navigateurs peuvent représenter ~1 M de points WebGL — c'est la fluidité interactive qui se dégrade, pas un plantage net.) Deux stratégies règlent le problème :
1. Rastérisation côté serveur — Datashader. Plutôt que d'envoyer les points au navigateur, Datashader (BSD-3-Clause) les regroupe dans une grille 2D de taille fixe et rend cette grille sous forme d'image, « en préservant fidèlement la distribution des données ». Son chiffre phare : un milliard de points en environ une seconde sur un ordinateur portable de 16 Go, avec passage à l'échelle hors mémoire et vers le GPU via Dask (introduction · guide HoloViews pour les grandes données). Traitez le chiffre du milliard de points par seconde comme le meilleur cas d'un éditeur — mais l'approche (re-regrouper à chaque zoom/panoramique) est véritablement la bonne pour les données denses.
import datashader as ds, datashader.transfer_functions as tf
cvs = ds.Canvas(plot_width=900, plot_height=400)
agg = cvs.points(df, "t", "price") # df can be a Dask frame larger than RAM
img = tf.shade(agg)
2. Sous-échantillonnage dépendant de la vue — plotly-resampler. Il conserve toute l'interactivité de Plotly mais ne rend jamais que les points que vous pouvez réellement voir. Son agrégation par défaut MinMaxLTTB réduit chaque trace à ~1 000 points tracés pour la vue courante, puis recharge les données à mesure que vous zoomez — la démo visualise plus de 110 millions de points de données de cette manière (article).
from plotly_resampler import FigureResampler
import plotly.graph_objects as go
fig = FigureResampler(go.Figure())
fig.add_trace(go.Scattergl(name="price"), hf_x=ts, hf_y=price) # 100M+ points
fig.show_dash()
Règle empirique : nuage de points/carte de chaleur dense de millions de points → Datashader ; longue série temporelle interactive → plotly-resampler.
Tracer les données de marché : chandeliers et OHLC
Pour un workflow orienté trading, la référence est mplfinance — le paquet de charting financier de l'organisation Matplotlib. Il prend un DataFrame pandas doté d'un DatetimeIndex et de colonnes Open/High/Low/Close et dessine des graphiques en chandeliers, OHLC, en ligne, Renko et Point & Figure, avec moyennes mobiles et volume intégrés :
import mplfinance as mpf
mpf.plot(df, type="candle", mav=(20, 50), volume=True, style="charles")
Au-delà de mplfinance :
- Chandeliers interactifs : le
go.Candlestickde Plotly, enveloppé dansplotly-resamplerune fois votre historique devenu long. - Graphiques en direct/en flux : le modèle serveur de Bokeh, ou des wrappers dédiés comme
lightweight-charts-python(un binding sur les lightweight-charts de TradingView) lorsque vous voulez exactement ce look de terminal de trading. - Rapports/backtests statiques : mplfinance directement en PNG.
La comparaison en un coup d'œil
| Bibliothèque | Type | Licence | Interactif | Idéal pour | À surveiller |
|---|---|---|---|---|---|
| Matplotlib | Statique | PSF/compatible BSD | Non | Contrôle total, impression/PDF | Verbeux, valeurs par défaut datées |
| Seaborn | Statique | BSD-3 | Non | Analyse exploratoire statistique | Retombe sur Matplotlib pour l'inhabituel |
| Plotly | Interactif | MIT | Oui | Tableaux de bord, graphiques de finance | Bundle lourd ; plafond WebGL de ~1 M points |
| Bokeh | Interactif | BSD-3 | Oui | Flux / applications de données | Pas automatiquement rapide sur de grosses données |
| Altair | Interactif | BSD-3 | Oui | Spécifications déclaratives, reproductibles | Plafond par défaut de 5 000 lignes |
| Plotnine | Statique | MIT | Non | Réflexes ggplot2 | Statique uniquement |
| Pygal | SVG | Open source (LGPL) | Léger | Graphiques vectoriels propres sur le web | Niche ; pas pour les grandes données |
| Datashader | Raster serveur | BSD-3 | Via HoloViews | 10⁶–10⁹ points | Une image, pas des marques vectorielles |
| mplfinance | Statique | Style BSD (org mpl) | Non | Chandelier / OHLC | Statique ; à coupler avec Plotly pour l'interactivité |
Chiffres de popularité vérifiés à la mi-2026 : Plotly ≈ 18,6 k étoiles / ≈ 1,24 Md de téléchargements ; Bokeh ≈ 20,4 k étoiles / 4,3 k forks. Les nombres d'étoiles et de téléchargements bougent en permanence — traitez-les comme des instantanés, et rappelez-vous que les téléchargements PyPI bruts incluent les CI et les miroirs, ce qui surestime l'adoption humaine.
Comment choisir, en une seule respiration
- Graphique statique rapide dans un notebook → Matplotlib.
- Analyse exploratoire statistique sur un DataFrame → Seaborn.
- Graphiques interactifs ou un tableau de bord → Plotly (ou Bokeh si c'est du flux / en forme d'application).
- Spécifications concises et versionnables → Altair (attention au plafond de 5 k lignes).
- Vous pensez en ggplot2 → Plotnine.
- Du SVG propre pour une page web ou un rapport → Pygal.
- Des millions à des milliards de points → Datashader (dense) ou plotly-resampler (longues séries temporelles).
- Chandeliers et données de marché → mplfinance pour le statique, Plotly pour l'interactif.
Choisissez celle qui correspond à la tâche, pas celle qui a le plus d'étoiles. La plupart des vrais projets finissent par en utiliser deux ou trois ensemble — Seaborn pour l'exploration, Plotly pour le tableau de bord, mplfinance pour le rapport de backtest — et c'est le bon résultat, pas un échec de la standardisation.
Méthodologie : les affirmations de cette revue ont été recoupées avec des sources primaires (dépôts GitHub des projets, PyPI et documentation officielle) et vérifiées de façon adversariale ; les chiffres sont des instantanés de la mi-2026. Les chiffres de performance signalés comme provenant des éditeurs (le milliard de points de Datashader, les 110 M de plotly-resampler) sont des meilleurs cas reproductibles, pas des bancs d'essai indépendants.