No existe una única librería de gráficos "mejor" en Python, y quien te diga lo contrario te está vendiendo algo. La respuesta honesta es que el campo se reparte entre un puñado de herramientas, cada una de las cuales gana en una tarea concreta: un gráfico estático con calidad de publicación, una estadística en una sola línea, un dashboard interactivo, una especificación declarativa que puedes versionar, o un gráfico que tiene que sobrevivir a cien millones de puntos. Esta review recorre las librerías que importan, en qué es genuinamente buena cada una, dónde se rompe y —porque este sitio trata de construir en Python para mercados— cómo manejan las velas y las series temporales grandes.
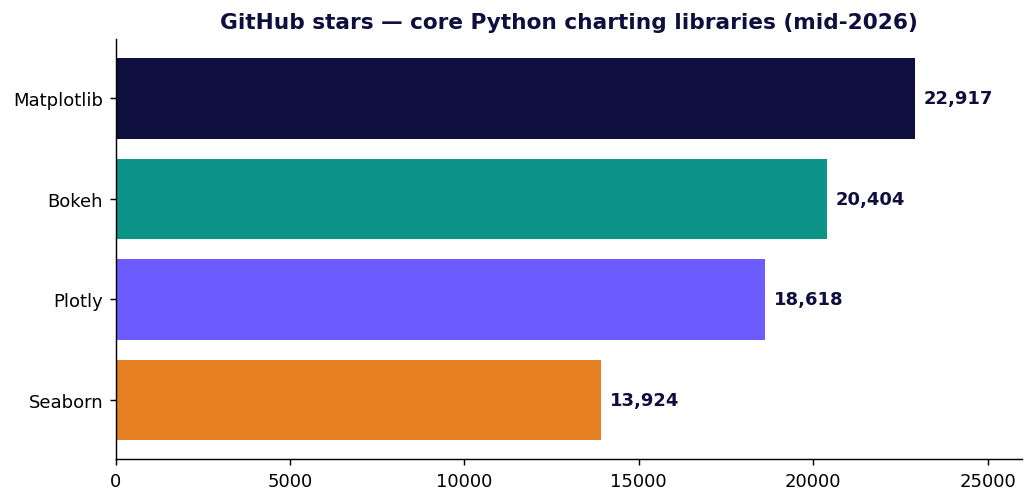
Cada recuento de estrellas, cifra de descargas y licencia que aparece abajo se contrastó con fuentes primarias (GitHub, PyPI, documentación oficial) a mediados de 2026. Cuando un número es el mejor caso autoinformado por un proveedor, se señala como tal.
El modelo mental: estático vs. interactivo
La primera bifurcación es si la salida es una imagen estática (PNG/SVG/PDF, renderizada una sola vez) o una figura interactiva (HTML/JS, con pan-zoom-hover en un navegador).
- Estático: Matplotlib, Seaborn, Plotnine — y Pygal, que produce un SVG con cierta interactividad.
- Interactivo: Plotly, Bokeh, Altair.
La segunda bifurcación —que solo te muerde cuando tus datos crecen— es dónde se dibujan los puntos: en el navegador (del lado del cliente, WebGL) o preagregados en el servidor en una imagen. Esa distinción es toda la historia del "nivel de escala" más abajo, y es la que la mayoría de las reviews se salta.
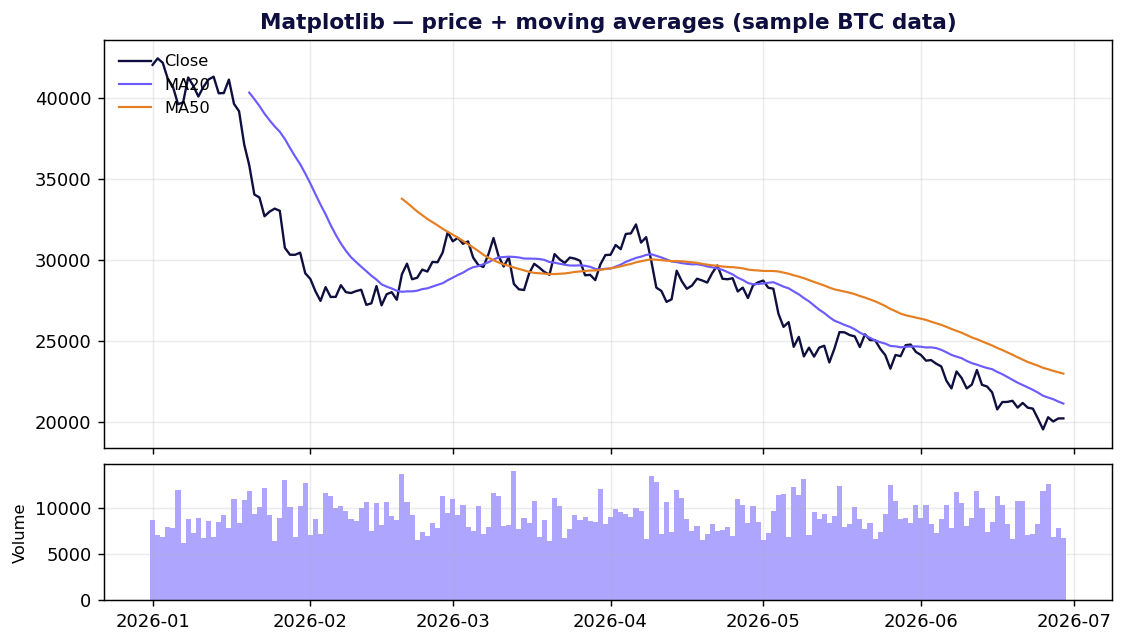
Matplotlib — el cimiento sobre el que todo se apoya
Matplotlib es la roca madre del trazado en Python. No es solo una librería; es el motor de renderizado sobre el que Seaborn, los valores por defecto de Plotnine, mplfinance y una docena más se construyen. Su licencia es permisiva —oficialmente "basada en la licencia PSF" y compatible con BSD—, así que puedes integrarla en un producto propietario y venderlo sin pensarlo dos veces (documentación de la licencia).
Fortalezas. Control total. Si puedes describir una marca sobre un lienzo 2D, Matplotlib puede dibujarla, y exporta un PDF/SVG vectorial nítido para impresión. Está instalado en todas partes y cualquier error que llegues a encontrar ya tiene una respuesta en Stack Overflow.
Debilidades. La API es célebremente bicéfala —una interfaz pyplot con estado al estilo MATLAB y una interfaz orientada a objetos Figure/Axes— y los tutoriales las mezclan sin pudor, que es justo el motivo por el que "why you hate matplotlib" es todo un género. Los valores por defecto están anticuados, y darle a un gráfico un aspecto moderno cuesta unas cuantas líneas de código de verdad.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(df.index, df["close"], lw=1.2)
ax.set_title("BTC-USD daily close")
fig.savefig("btc.png", dpi=150, bbox_inches="tight")
Úsalo cuando necesites una figura estática lista para imprimir, o estés construyendo una herramienta de más alto nivel y quieras un lienzo que controles por completo.
Seaborn — gráficos estadísticos sin el boilerplate
Seaborn es una capa fina y con criterio propio sobre Matplotlib (BSD-3-Clause) que convierte diez líneas de pelea con los ejes en una. "Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos" y se integra de forma estrecha con pandas — distribuciones, regresiones, heatmaps y small-multiples facetados son todos una sola llamada.
import seaborn as sns
sns.set_theme()
sns.lineplot(data=returns, x="date", y="ret", hue="symbol")
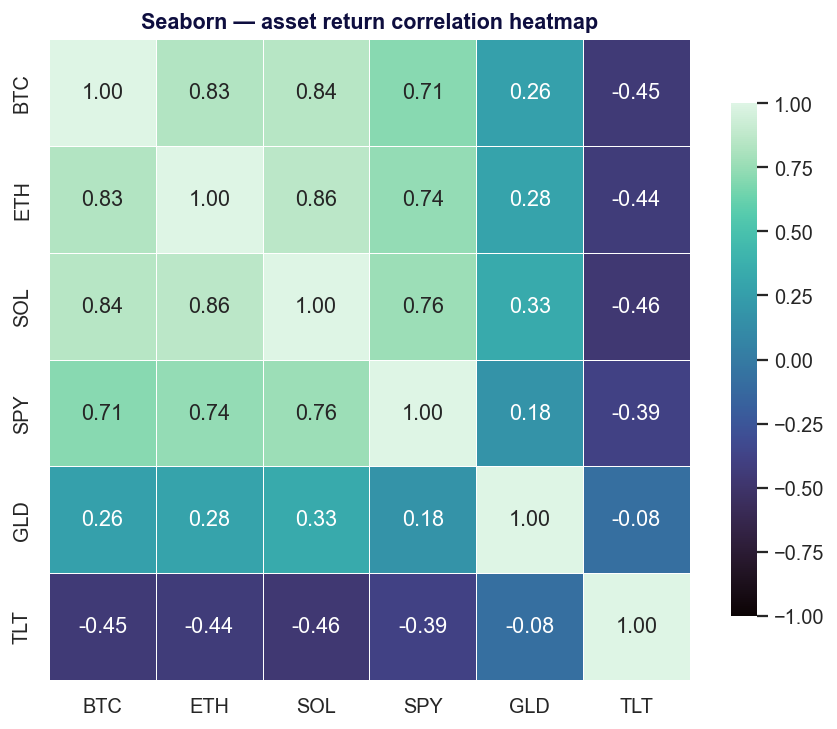
Fortalezas. Los mejores valores por defecto para estadística de su categoría; precioso desde el primer momento; el primer recurso obvio para el análisis exploratorio de datos.
Debilidades. Hereda la naturaleza estática de Matplotlib (sin interactividad) y, cuando necesitas un gráfico para el que no tiene función, de todos modos terminas bajando a Matplotlib en crudo. Es una capa de comodidad, no una vía de escape del motor.
Úsalo cuando estés haciendo EDA sobre un DataFrame y quieras heatmaps de correlación, distribuciones o gráficos de regresión rápido.
Plotly — el interactivo por defecto
Plotly.py es la opción interactiva más adoptada. Tiene licencia MIT, está construida sobre plotly.js, y las cifras no dejan lugar a dudas: en torno a 18,6k estrellas en GitHub y unos 1,24 mil millones de descargas históricas en PyPI — del orden de 61 millones de descargas en los últimos 30 días (PyPI · estadísticas de descargas). Los tooltips al pasar el cursor, el zoom, el pan y el alternado de la leyenda vienen gratis, y la misma figura se renderiza en un notebook, en una app de Dash o en un archivo HTML estático.
import plotly.graph_objects as go
fig = go.Figure(go.Candlestick(
x=df.index, open=df.open, high=df.high, low=df.low, close=df.close,
))
fig.update_layout(title="BTC-USDT", xaxis_rangeslider_visible=False)
fig.show()
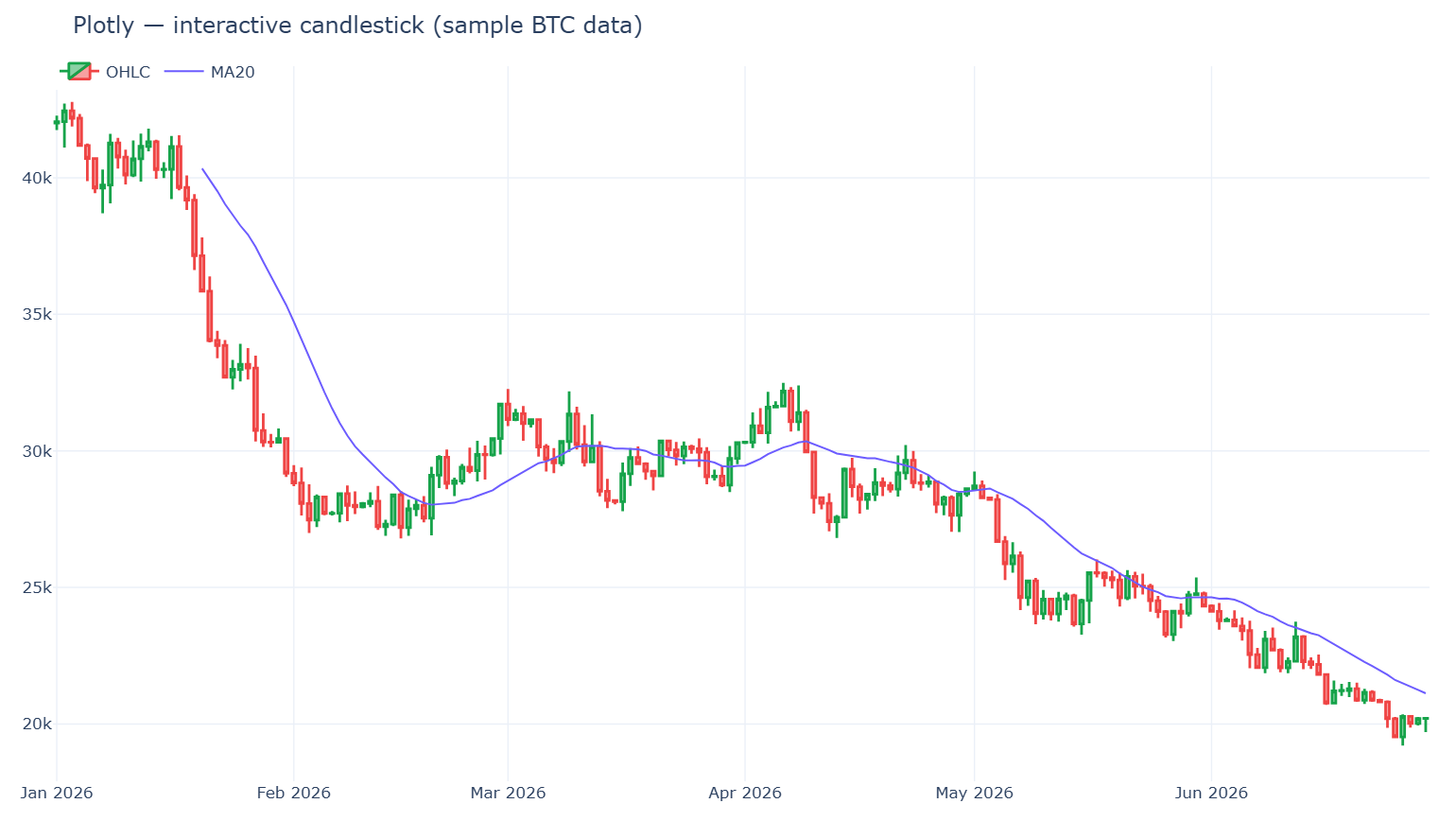
Fortalezas. Interactividad con cero JavaScript; tipos de gráfico financiero de primera clase (go.Candlestick, go.Ohlc); el camino hacia un dashboard completo (Dash) es corto.
Debilidades. El bundle de plotly.js es pesado — un coste real para sitios sensibles al tiempo de carga de la página (análisis de tiempos de bundle). Y hay un techo de renderizado duro: con trazas WebGL (go.Scattergl) puedes representar hasta ~1 millón de puntos, pero los navegadores solo permiten de 8 a 16 contextos WebGL por página, así que en la práctica obtienes de 4 a 8 figuras WebGL antes de chocar con "Too many active WebGL contexts" (documentación de rendimiento de Plotly). El zoom/pan interactivo fluido aguanta de forma realista hasta ~100–200k puntos.
Úsalo cuando quieras gráficos interactivos o dashboards, sobre todo financieros, y tus series tengan de miles a unos pocos millones de puntos.
Bokeh — interactivo pensado para datos grandes y en streaming
Bokeh (BSD-3-Clause, ~20,4k estrellas / 4,3k forks) es el principal rival interactivo de Plotly, con un centro de gravedad distinto: es "una librería de visualización interactiva para navegadores web modernos" orientada a conjuntos de datos grandes y en streaming y a apps dirigidas desde el servidor (el servidor de Bokeh puede empujar actualizaciones en vivo a un gráfico a través de un websocket).
Una salvedad honesta que el marketing no te dará: el "alto rendimiento" es en parte autodescripción. Informes del mundo real muestran que el hover/los tooltips se atascan con conjuntos de datos tan pequeños como ~50k puntos, así que no es automáticamente rápido con datos enormes — sigues teniendo que recurrir a la agregación (más abajo). Trata la ventaja de Bokeh como streaming y arquitectura de apps, no como recuento bruto de puntos.
from bokeh.plotting import figure, show
p = figure(x_axis_type="datetime", title="BTC-USD", height=350)
p.line(df["date"], df["close"])
show(p)
Úsalo cuando estés construyendo un dashboard que se actualiza en vivo o una app de datos dirigida desde Python y quieras control del lado del servidor sobre la interactividad.
Altair — una gramática declarativa de gráficos
Altair es una librería declarativa: describes qué codificar (esta columna a x, aquella al color) y el motor Vega-Lite decide cómo dibujarlo. Los gráficos son especificaciones JSON, lo que los hace componibles y amigables con los diffs.
La trampa con la que tropieza todo recién llegado: por defecto, Altair se niega a trazar más de 5.000 filas, lanzando un MaxRowsError. Es una barrera deliberada (Altair incrusta los datos como JSON en la especificación), no una incapacidad para manejar datos — y levantarla es cuestión de una línea:
import altair as alt
alt.data_transformers.disable_max_rows() # o usa el backend VegaFusion para ~100k+
alt.Chart(df).mark_line().encode(x="date:T", y="close:Q")
Es una fuente de frustración recurrente precisamente porque el error aparece sobre lo que se siente como un frame "pequeño" de 35k filas (documentación de grandes conjuntos de datos).
Úsalo cuando valores especificaciones de gráficos concisas, declarativas y reproducibles y tus datos sean modestos — o estés dispuesto a cablear VegaFusion para los frames más grandes.
Plotnine y Pygal — completando el cuadro
- Plotnine es un port casi fiel de la gramática de gráficos de
ggplot2de R (licencia MIT). Si vienes de R o piensas enaes()+ capas degeom_*, es la API más natural de esta lista. Renderiza a través de Matplotlib, así que es estático.
python
from plotnine import ggplot, aes, geom_line
(ggplot(df, aes("date", "close")) + geom_line())
- Pygal produce gráficos SVG — independientes de la resolución, estilizables con CSS y diminutos para incrustar en un informe o una página web. Es una elección de nicho: encantadora para gráficos vectoriales limpios en una página web, no pensada para datos grandes ni interactividad pesada.
Cuando tus datos crecen: el nivel de escala
Aquí es donde las elecciones ingenuas se vienen abajo. Una vez que pasas del millón de puntos, no puedes simplemente entregárselos al navegador. (Para ser precisos sobre un mito: los navegadores pueden representar ~1M de puntos WebGL — lo que se degrada es la fluidez interactiva, no es un crash duro.) Dos estrategias lo arreglan:
1. Rasterización del lado del servidor — Datashader. En lugar de enviar puntos al navegador, Datashader (BSD-3-Clause) los agrupa en una cuadrícula 2D de tamaño fijo y renderiza esa cuadrícula como una imagen, "preservando fielmente la distribución de los datos". Su cifra estrella: mil millones de puntos en alrededor de un segundo en un portátil de 16 GB, escalando out-of-core y a la GPU vía Dask (introducción · guía de grandes datos de HoloViews). Trata el número de mil millones de puntos por segundo como un mejor caso del proveedor — pero el enfoque (reagrupar en cada zoom/pan) es genuinamente el correcto para datos densos.
import datashader as ds, datashader.transfer_functions as tf
cvs = ds.Canvas(plot_width=900, plot_height=400)
agg = cvs.points(df, "t", "price") # df puede ser un frame de Dask más grande que la RAM
img = tf.shade(agg)
2. Submuestreo dependiente de la vista — plotly-resampler. Esto conserva toda la interactividad de Plotly pero solo renderiza los puntos que realmente puedes ver. Su agregación por defecto MinMaxLTTB reduce cada traza a ~1.000 puntos trazados para la vista actual y luego vuelve a buscar datos a medida que haces zoom — la demo visualiza más de 110 millones de puntos de datos de esta manera (artículo).
from plotly_resampler import FigureResampler
import plotly.graph_objects as go
fig = FigureResampler(go.Figure())
fig.add_trace(go.Scattergl(name="price"), hf_x=ts, hf_y=price) # más de 100M de puntos
fig.show_dash()
Regla general: scatter/heatmap denso de millones de puntos → Datashader; serie temporal interactiva larga → plotly-resampler.
Graficar datos de mercado: velas y OHLC
Para un flujo de trabajo enfocado en trading, lo que destaca es mplfinance — el paquete de gráficos financieros de la organización Matplotlib. Toma un DataFrame de pandas con un DatetimeIndex y columnas Open/High/Low/Close y dibuja gráficos de velas, OHLC, línea, Renko y Point & Figure, con medias móviles y volumen incorporados:
import mplfinance as mpf
mpf.plot(df, type="candle", mav=(20, 50), volume=True, style="charles")
Más allá de mplfinance:
- Velas interactivas: el
go.Candlestickde Plotly, envuelto enplotly-resamplercuando tu histórico se vuelve largo. - Gráficos en vivo/streaming: el modelo de servidor de Bokeh, o wrappers dedicados como
lightweight-charts-python(un binding sobre lightweight-charts de TradingView) cuando quieres ese aspecto exacto de terminal de trading. - Informes estáticos/backtests: mplfinance directo a PNG.
La comparación de un vistazo
| Librería | Tipo | Licencia | Interactivo | Mejor para | Ojo con |
|---|---|---|---|---|---|
| Matplotlib | Estático | PSF/compatible BSD | No | Control total, impresión/PDF | Verboso, valores por defecto anticuados |
| Seaborn | Estático | BSD-3 | No | EDA estadístico | Baja a Matplotlib para lo inusual |
| Plotly | Interactivo | MIT | Sí | Dashboards, gráficos financieros | Bundle pesado; techo WebGL de ~1M de puntos |
| Bokeh | Interactivo | BSD-3 | Sí | Streaming / apps de datos | No es rápido por sí solo con datos grandes |
| Altair | Interactivo | BSD-3 | Sí | Especificaciones declarativas y reproducibles | Límite por defecto de 5.000 filas |
| Plotnine | Estático | MIT | No | Memoria muscular de ggplot2 | Solo estático |
| Pygal | SVG | Open source (LGPL) | Ligero | Gráficos vectoriales limpios en la web | De nicho; no para datos grandes |
| Datashader | Ráster en servidor | BSD-3 | Vía HoloViews | 10⁶–10⁹ puntos | Una imagen, no marcas vectoriales |
| mplfinance | Estático | Estilo BSD (org mpl) | No | Velas / OHLC | Estático; combínalo con Plotly para interactividad |
Cifras de popularidad verificadas a mediados de 2026: Plotly ≈18,6k estrellas / ≈1,24B descargas; Bokeh ≈20,4k estrellas / 4,3k forks. Los recuentos de estrellas y descargas se mueven constantemente — trátalos como instantáneas, y recuerda que las descargas brutas de PyPI incluyen CI y mirrors, así que sobreestiman la adopción humana.
Cómo elegir, en una sola frase
- Gráfico estático rápido en un notebook → Matplotlib.
- EDA estadístico sobre un DataFrame → Seaborn.
- Gráficos interactivos o un dashboard → Plotly (o Bokeh si es de streaming / con forma de app).
- Especificaciones concisas y versionables → Altair (ojo con el límite de 5k filas).
- Piensas en ggplot2 → Plotnine.
- SVG limpio para una página web o un informe → Pygal.
- De millones a miles de millones de puntos → Datashader (denso) o plotly-resampler (series temporales largas).
- Velas y datos de mercado → mplfinance para estático, Plotly para interactivo.
Elige la que encaje con el trabajo, no la que tenga más estrellas. La mayoría de los proyectos reales terminan usando dos o tres de estas juntas — Seaborn para la exploración, Plotly para el dashboard, mplfinance para el informe del backtest — y ese es el resultado correcto, no un fracaso en estandarizar.
Metodología: las afirmaciones de esta review se contrastaron con fuentes primarias (repositorios de GitHub de los proyectos, PyPI y documentación oficial) y se verificaron de forma adversarial; las cifras son instantáneas de mediados de 2026. Los números de rendimiento marcados como cifras del proveedor (los mil millones de puntos de Datashader, los 110M de plotly-resampler) son mejores casos reproducibles, no benchmarks independientes.